
本文是全系列中第5 / 5篇:高频交易策略的思考
转载自 FMZ.COM ,作者:小草
文章探讨了数字货币高频交易策略,包括利润来源(主要来自市场剧烈波动和交易所手续费返佣),挂单位置和仓位控制的问题,以及用帕累托分布对成交量进行建模的方法。此外,还引用了币安提供的逐笔成交和最优挂单数据进行回测,并计划在后续文章中深入讨论高频交易策略的其他问题。
以前我曾经写过两篇关于数字货币高频交易的两篇文章数字货币高频策略详细入门,5天赚80倍,高频策略的威力。但只能算是经验分享,泛泛而谈。本次我计划写个系列文章, 从头开始介绍高频交易的思路, 希望尽量简洁明了,但由于本人水平有限,对高频交易的理解不算深入,本文只算抛砖引玉,希望大神指正。
高频利润来源
以前的文章提到过,高频策略特别适合行情上下波动非常剧烈的行情。考察一个交易品种在短时间内的价格变化,由总的趋势和震荡组成。如果我们能准确的预测趋势的变化,当然能够赚钱,但这也是最难的,本文主要介绍高频的maker策略,将不涉及这个问题。在震荡行情中,策略上下挂单,如果成交的足够频繁,利润空间足够大,是能够覆盖因趋势造成的可能损失,这样不预测行情也能盈利。目前交易所maker成交都有手续费返佣,这也是利润的组成部分,竞争越充分,rebate所占的比例也应该也高。
要解决的问题
1.策略同时挂买单和卖单,第一个问题就是在哪里挂单。挂的离盘口越近,成交的概率越高,但在剧烈波动的行情中,瞬间成交的价格可能离盘口较远,挂的那太近没有能吃到足够的利润。挂的太远的单子成交概率又低。这是一个需要优化的问题。
2.控制仓位。为了控制风险,策略就不能长时间累计过多的仓位。可以通过控制挂单距离、挂单量、总仓位限制等办法解决。
为了能达到上面的目的,需要对成交概率概率、成交的利润、行情估计等多方面进行建模估计,这方面的文章和论文很多,以High-Frequency Trading, Orderbook等关键词可以找到。网上也有很多推荐,这里就不展开。另外最好还要建立一个可靠快速的回测系统,虽然高频策略很容易通过实盘来验证策略的有效性,但回测还是能提供更多的思路,降低试错的成本。
需要的数据
币安提供了逐笔成交和最优挂单数据供下载,深度数据需要在白名单中用API下载,也可以自己收集。回测用途使用归集的成交数据就可以。本文以HOOKUSDT-aggTrades-2023-01-27的数据为例。
逐笔成交有以下列:
- agg_trade_id:归集成交单的id,
- price:成交价
- quantity:成交的数量
- first_trade_id:归集交易可能有几笔同时成交,只统计一条数据,这是第一笔成交的id
- last_trade_id:最后成交的id
- transact_time:成交时间
- is_buyer_maker:成交方向,True代表买单maker成交,卖单是taker
可以看到当天有66万条成交数据,成交很活跃。csv将附在评论区。

单笔成交量建模
先对数据进行处理,把原始的trades分为了买单主动成交组和卖单主动成交组。另外原始聚合交易的数据是同一时间同一个价格同一方向为一条数据,可能会发生一笔主动的买单量为100,如果分为多笔成交且价格不一样,如分为了60和40两笔,会产生两条数据,影响买单成交量的估计。因此在需要根据transact_time再聚合一次。聚合后数据量减少了14万条。
print(trades.shape[0] - (buy_trades.shape[0]+sell_trades.shape[0]))
146181
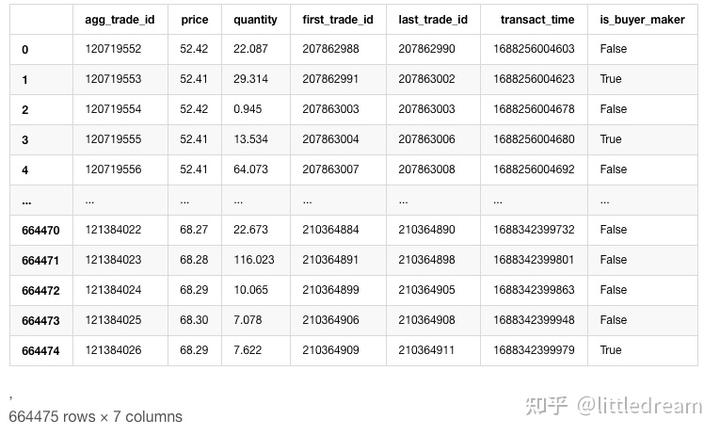
以买单为例,先画出直方图,可以看到长尾效应非常明显,大部分数据集中在最左侧一点,但也有少量的大成交分布在尾巴上。
buy_trades['quantity'].plot.hist(bins=200,figsize=(10, 5));
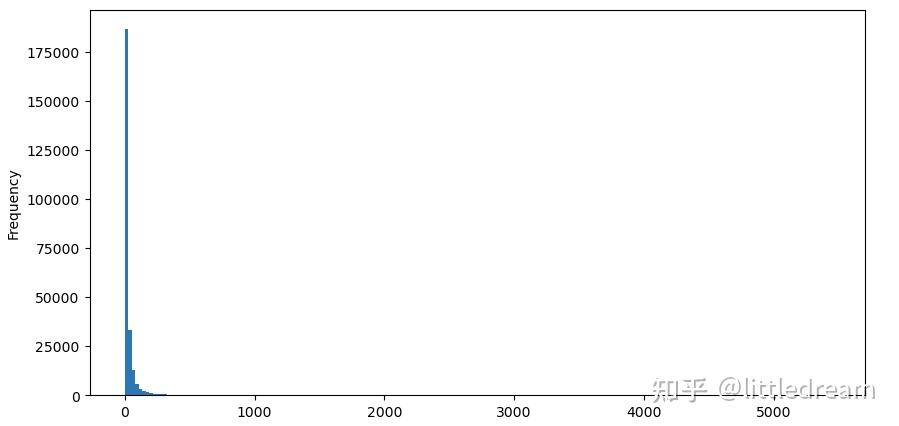
为了观察方便,截掉尾部观察.可以看到成交量越大,出现频率越低,且减少的趋势更快。
buy_trades['quantity'][buy_trades['quantity']
关于成交量满足的分布相关研究很多。其满足幂律分布(Power-law distribution)又叫帕累托分布,是统计物理学和社会科学中常见的一种概率分布形式。在幂律分布中,事件的大小(或频率)的概率正比于该事件大小的某个负指数。这种分布形式的主要特点是大事件(即那些远离平均值的事件)的发生频率比在许多其他分布中预期的要高。这正是成交量分布的特点。帕累托分布的形式为:P(x) = Cx^(-α)。下面将实证下。
下面这张图表示成交量大于某个值的概率,蓝线为实际概率,橙线为模拟的概率,这里先不要纠结具体的参数,可以看到样子确实很满足帕累托分布。由于订单量大于0的概率为1,且为了满足标准化,其分布方程形式应该如下:

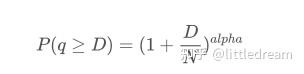
其中N为标准化的参数。这里选择平均成交量M,alpha选择-2.06 。具体alpha的估计可以通过当D=N是的P值反算出。具体的:alpha = log(P(d>M))/log(2) 。选择不同的点alpha取值会稍有差异。

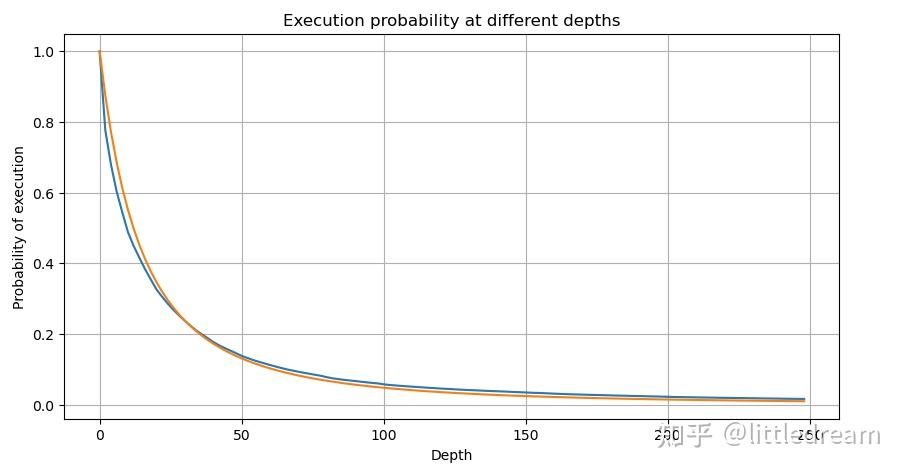

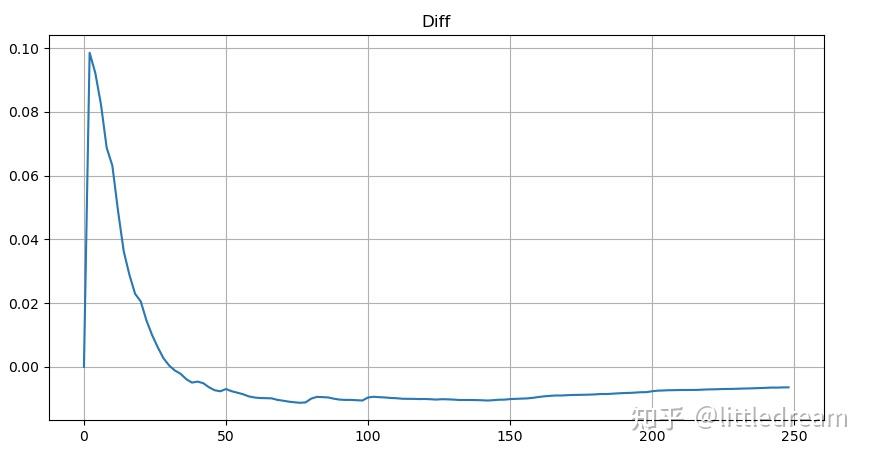
但这个估计只是看起来像,上图我们画出模拟值和实际值的差。当成交量较小时偏差很大,甚至接近10%。可以通过参数估计时选择不同的点来使这个点的概率更精准,但也解决不了偏离的问题。这是幂律分布和实际分布的差异决定的,为了得到更准确的结果,需要对幂律分布的方程进行修正。具体的过程不赘述,总之灵光闪过,发现实际应该如下:

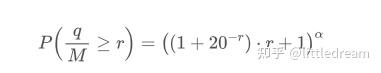
为了简介这里用r = q/M 代表标准化的成交量。可以用上面同样的方式估计参数。下面的图可以看到修正后最大偏差不超过2%, 理论上可以继续修正,但这个精度也够用了。

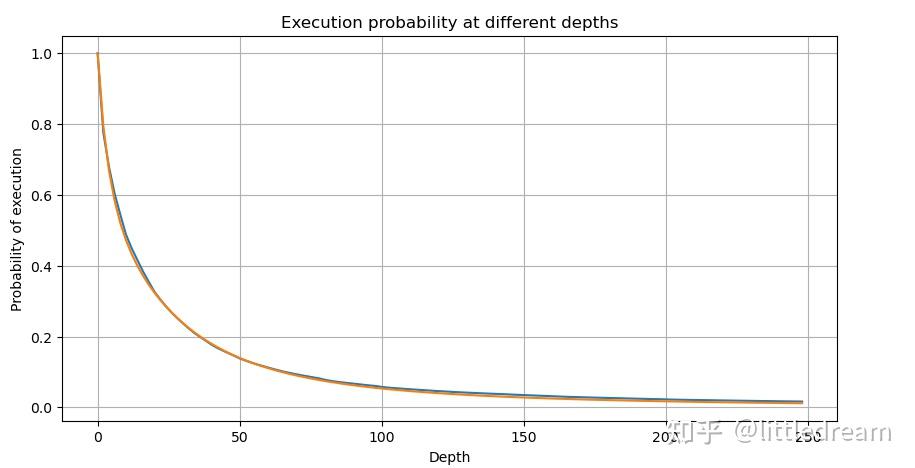

有了对成交量分布的估计方程,注意方程的概率不是真实的概率,而是一个条件概率。此时可以回答这个问题,如果下一笔订单发生,这个订单大于某个值的概率是多少?也可以说,不同深度的订单成交的概率是多少(理想情况,不那么严谨,理论上订单簿有新增订单和撤单,以及同深度有排队)。
写到这里篇幅已经差不多了,还有很多疑问需要解答,下面的系列文章将尝试给出答案。
文章来源于互联网:高频交易策略的思考(一)

