
以下内容来自于腾讯PCG工程师Chaoweili
【第1部分】 概念和基础
架构设计:高性能、高可用、高扩展
第1章 架构基础
1.1 “架构”到底指什么
1.1.1 系统与子系统
系统:


子系统:


1.1.2 模块与组件
模块:


组件:


从逻 辑的角度来拆分后得到的单元就是“模块”,从物理的角度来拆分系统得到的单元就是“组件”; 划分模块的主要目的是职责分 离,划分组件 的主要目的是单元复用
1.1.3 框架与架构
框架:


架构:


框架关注的是“规范”,架构关注的是“结构”。框架: Framework,架构:Architecture
1.1.4 重新定义架构
软件架构:指软件系统的顶层结构!
1.2 架构设计的目的
架构设计的主要目的是:为了解决复杂度带来的问题。
也为了高性能、高可用、可扩展
1.3 复杂度来源
1.3.1 高性能
为了高性能,单台性能,扩张多多台集群性能,将业务分配功能模块,分解到各个子系统。带来了系统的机器复杂
单机复杂度
集群复杂度
任务分配
任务分解
1.3.2 高可用
高可用指“系统无中断地执行其功能”的能力,代表系统的可用性程度,是进行系统设计
时的准则之 一。一般都是通过“冗余”增加可用性,带来了复杂性。
1)计算高可用:双机/多机
2)存储高可用:备份数据,减少或规避数据不一致对业务造成的影 晌 。
高可用状态决策:无论计算高可用,还是存储高可用,其基础都是“状态决策”
几种 常见的决策方式:
1) 独裁式
只有一个决策者,如果决策者异常,整个系统就异常。
2) 协商式
两个独立的个体交流信息,然后根据规则进行决策,最常用的协商式决策就是主备决策
3) 民主式
民主式决策指的是多个独立的个体通过投票的方式来进行状态决策。例如, ZooKeeper集 群在选举 leader 时就是采用这种方式,
多个个体会出现“脑裂”,解决办法:投票节点数必须超过系统总节点数一半(过半原则)
1.3.3 可扩展性
可扩展性:无需或少量更改满足未来需求,不必整个重写或者重构
预测变化:不能全无扩展,也无需全都扩展
应对变化:抽象稳定层和变化层
1.3.4 低成本
大公司创造新的技术;小公司引入新技术。解决某个关键问题
1.3.5 安全
功能安全:
xss 攻击、 cs盯攻击、 SQL 注入、 Windows 漏洞、密码破解
代码实现上的漏洞、开源框架的漏洞
架构安全:
防火墙,依靠运营商或者云服务商强大的带宽和流量清洗能力
1.3.6 规模
功能越来越多、数据越来越多,引起系统复杂度上升
第2章 架构设计原则
2.1 合适原则
“合适”优于“业界领先”
系统架构设计要考虑人力物力选择合适的,不激进的造轮子,一步步的发展和优化
2.2 简单原则
“简单”优于“复杂”
结构复杂性,逻辑复杂性,都存在问题,如简单的和复杂的方案都满足需求,选择简单的
2.3 演化原则
“演化”优于“一步到位”
不贪大贪全,不全量照搬,分析主要问题,选择合理架构快速落地,然后在运行中不断优化完善演化架构。
2.4 本章小结
架构设计原则:合适、简单、演化
第3章 架构设计流程
3.1 有的放矢—识别复杂度
分析系统的复杂性,明确目标。架构复杂性主要源于:高性能、高可用、可扩展。一个系统往往只涉及一方面。从多个方案中选性价比最高的方案
3.2 按图索骥—设计备选方案
分析复杂度,有了目标后,开始方案设计。
高可用的主备方案、集群方案,高性能的负载均衡、多路复 用,可扩展的分层、插件化等技术,绝大部分时候我 们 有了明确的目标后,按图索骥就能够找 到可选的解决方案。在现有成熟技术上选择组合来满足需求,实在没有时才考虑创新。
方案设计:一个主要方案,多个备选方案。各个方案要差异明显,其中备选方案不一定基于现有技术,不一定要很详细。
3.3 深思熟虑—评估和选择备选方案
方案确认挑战:


方案质 量属性点有::性能、可用性、硬件成本、项目投入、复杂度、安全性、可扩展性等。
遵循架构设计原则: “合适原则”和“简单原则”。 避免贪大求全,基本上某个质量属性能够满足一定时期内业务发展就可以了
例子:
1)业务背景


2)备选方案设计


3)备选方案360度环评


3.4 精雕细琢—详细方案设计
方案评审确认后,进一步细化,例如ES索引划分、数据库分表、Ngnix负载均衡(轮询、加权轮询、ipHash、fair响应时间、urlHash)等
【第2部分】 高性能架构模式
第4章 存储高性能
4.1 关系数据库
4.1.1 读写分离
读写分散到不同节点上

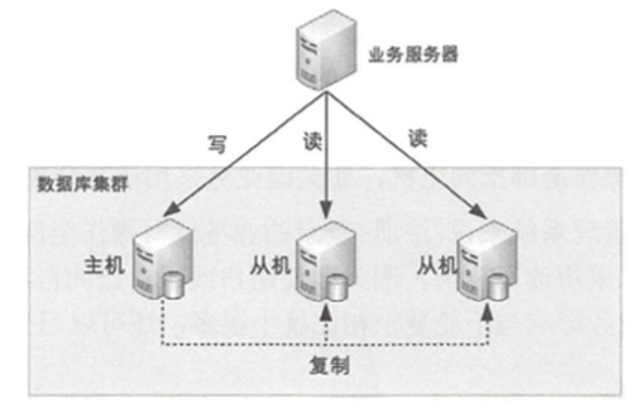
读写分离的基本实现如下:




解决主从复制延迟有几种常见的方法:


4.1.2 分库分表
常见的分散存储 的方法有“分库”和“分表”两大类
1) 分库
按“业务模块”将分库
问题:


2) 分表
a. 垂直分表:
按字段进行分表,一些字段在A表,一些字段在B表
b. 水平分表:
表行特别大,按一定算法分表比如用户ID分段,订单IDhash等分表。
分表方法:


一些问题处理:


4.1.3 实现方法
可以实现一些通用中间件或者使用开源中间件,来实现分裤分表的各种操作。

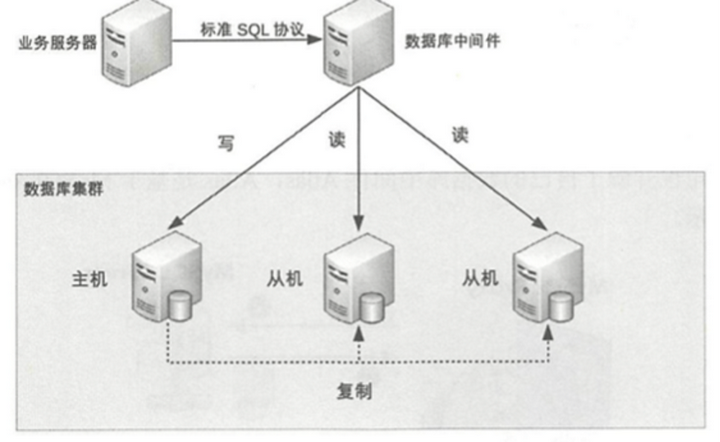
4.2 NoSQL
常见的 NoSQL 方案有如下 4 类。


4.2.1 K-V存储
Key-Value存储,代表:redis。
redis的事物只保证:隔离性(I)和一致性(C),无法保证原子性(A)和持久性(D)


4.2.2 文档数据库
文档数据:no-schema,可以存储和读取任意的数据,大部分文档数据库存储的数据格式是JSON(或者BSON)。
优点:自描述,无需事先定义,新增字段无需改表结构,可以很容易存储复杂数据。特别适合电商和游戏这类的业务场景。以电商为例 , 属性差异很大。例如,冰箱的属性和笔记本电脑的属性差异非常大。
缺点:不支持事务;无法join。例如MongoDB存储商品,可能库存被扣了,订单没有生成。
文档数据库,一般作为关系数据库的一种补充,比较适合电商和游戏场景,例如,冰箱的属性和笔记本电脑的属性差异非常大
例如:库存和订单用关系型数据库;商品详情用文档数据库存储。

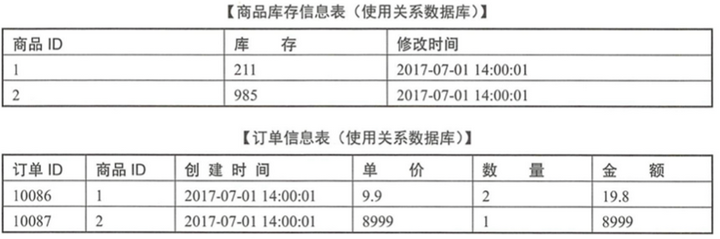


4.2.3 列式数据库
关系型数据库:按行进行存储的;
列式数据库:按列进行存储。
优点:减少IO(只读需要字段)、高压缩比(列上有更多重复内容,8:1 ~ 30:1)
缺点:由于高压缩比,更新会先解压,修改,再压缩写入
应用:应用在离线的大数据分析和统计场景中,因为这种场景主要是针对部分列进行操作,且数据写入后就无须再更新删除
4.2.4 全文搜索引擎
正排索引:基本原理是建立文档到单词的索引
倒排索引(Inverted index反向索引):是一种索引方法,其基本原理是建立单词到文档的索引。


ElasticSearch: 是分布式的文挡存储方式。 每个字段的所有数据都是默认被索引的 ,即每个字段都高为了快速检索设置的专用倒排索引。
4.3 缓存
为了提升存储系统性能,使用缓存,一次生成,多次读取,避免每次都直接访问存储
1) 需要复杂计算才能得出的数据,存储无能为力。
2) 读多写少:绝大部分都是读多写少,减少存储读压力
4.3.1 缓存穿透
1) 缓存穿透:缓存没有数据,直接去查询存储
2) 穿透原因:zookeeper
a. 首次读取:读取后下一次就可以直接读缓存
b. 数据在存储中也不存在:穿透一次数据库,在缓存中记录是空Key
c. 生成缓存耗时大:读取时刚好还计算缓存内容。安全监控非法查询拦截,加到缓存时间
4.3.2 缓存雪崩
缓存雪崩:缓存失效,大量请求来,每个请求都触发一个数据读取和缓存数据计算过程,造成系统存储系统性能急剧下降,甚至宕机,造成整个系统瘫痪。
缓存雪崩有两种处理方法:
1) 更新锁机制
a. 同一时刻只有一个线程建立缓存
b. 对于分布式系统,每个节点都同时建立缓存,也会冲击缓存,可以用zookeeper建立分布式锁来实现缓存读数据库更新逻辑
2) 后台更新机制:缓存本身永久有效,后台定时更新或者消息通知触发更新
4.3.3 缓存热点
缓存热点:对于特别热点的数据,所有服务都请求同一份缓存数据,导致缓存也有压力。
解决办法:缓存多份,hash选取一个节点去读取。
第5章 计算高性能
磁盘、操作系统、 CPU、内存、缓存、网络、编 程语 言 、架构等都有可能影响系统性能。
一 行不恰当的 debug 日志,就可能将服 务器的性能从3万TPS降低到8。一个tcp_nodelay参数, 就可能将响应时间从2ms延 长到 40ms
高性能方法:1)单机性能; 2)集群
5.1 单服务器高性能
单机性能关键就是网络编程模型:1)处理链接管理;2)处理请求
两个设计点最终都和操作系统的 I/O 模型及进程模型 :(1) IO模型:阻塞、非阻塞、同步、异步;(2)进程模型:单进程、 多进程、多线程。
5.1.1 PPC
PPC(Process per Connection):有连接来fork子进程处理 。

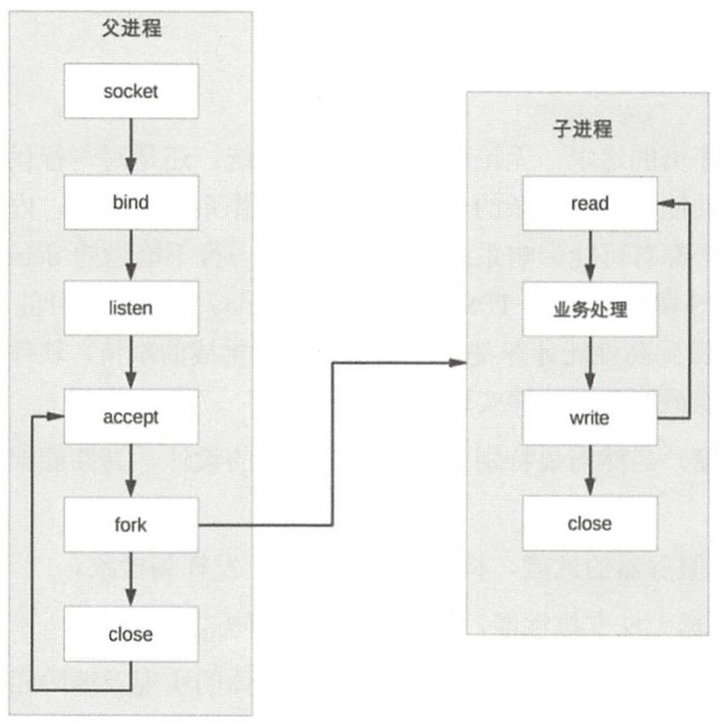


简单,适用量不大的情况:1)fork成本大 2)父子进程通信管理成本大 3)进程多了对系统也有压力
5.1.2 prefork
prefork: 预先fork子进程池子,来处理随时回来的请求,减少fork代价。
惊群现象:一个请求来了,只有一个子进程能 accept成功 , 但所有阻塞在 accept上的子进程都会被唤醒,这样就导致 了不必要的进程调度和上下文切换。 (linux2.6已经解决惊群现象)
5.1.3 TPC
TPC (Thread per Connection ):每次有新的连接就新建一个线程去专门处理请求。 比进程轻量

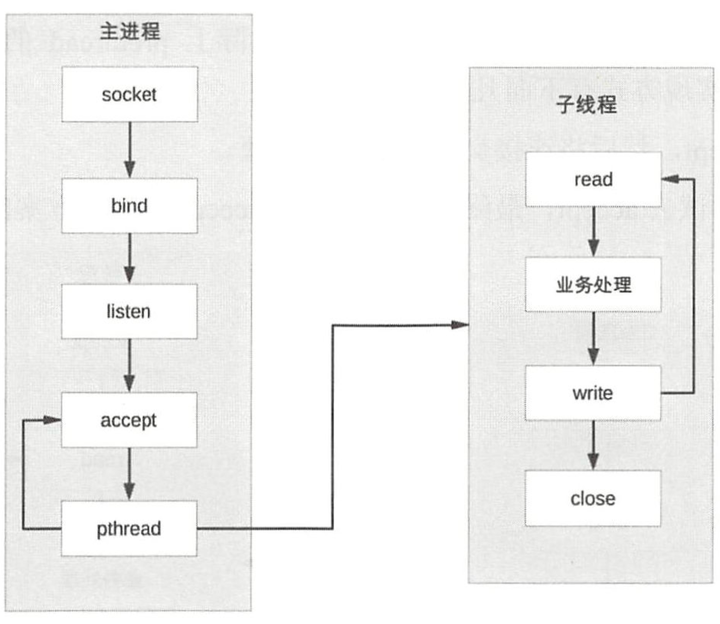
和 PPC 相比,主进程不用“ close”连接了。原因是在于子线程 是共享主进程的进程空间的,连接的文件描述符并没有被复制,因此只需要一次 close 即可 。
5.1.4 prethread
prethread:预先创建线程
5.1.5 Reactor
IO多路复用:一条连接上传 输多种数据。


Reactor(反应堆):IO多路复用结合线程池。I/O 多路复用 统一监昕事件,收到事件后分配( Dispatch)给某个进程。包括 Reactor和处理资源池 (进程池或线程池),其中 Reactor 负责监听和分配事件,处理资源池负责处理事件
(1)单 Reactor 单进程/单线程

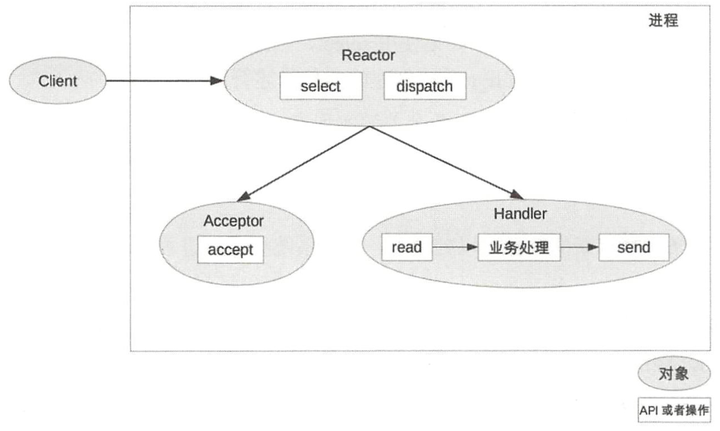
流程:


优点:


缺点:


(2)单 Reactor 多线程

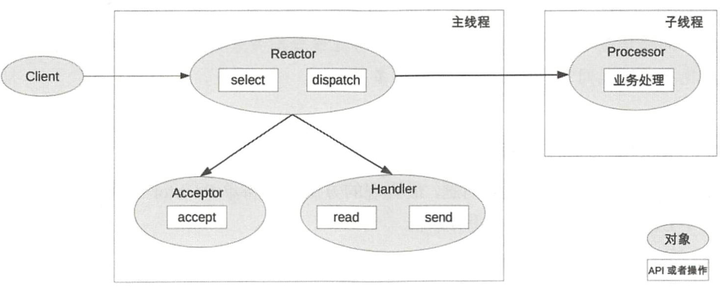
流程:


优点:充分利用多核CPU
缺点:


(3)多 Reactor多进程/线程

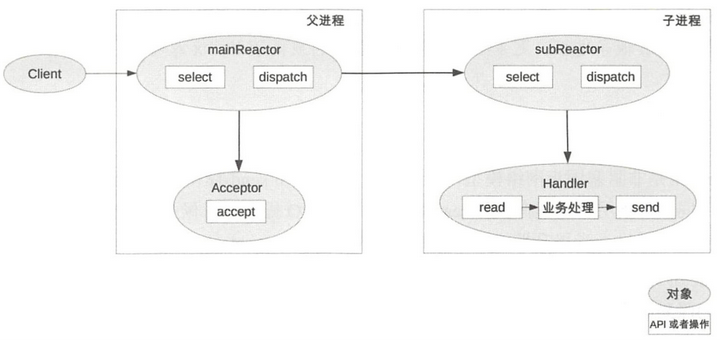
流程:


优点:


案例:


5.1.6 Proactor
Reactor 是非阻塞同步网络模型( read 和 send 操作都需要用户进程同步操作)
异步网络模型 Proactor:把 I/O 操作 改为异步。



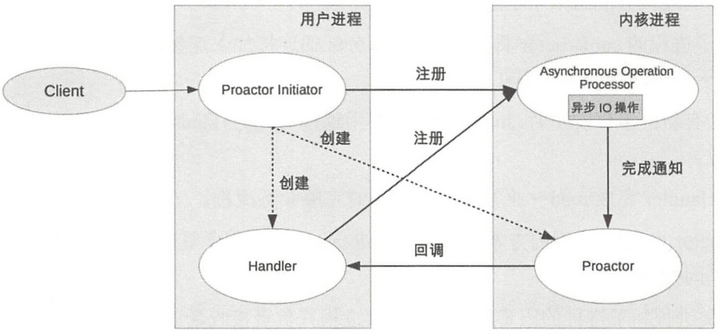


异步IO实现:


5.2 集群高性能
5.2.1 负载均衡分类
常见的负载均衡系统: 1)DNS 负载均衡、2)硬件负载均衡、3)软件负载均衡。
1) DNS 负载均衡
域名解析按地区给不同的ip

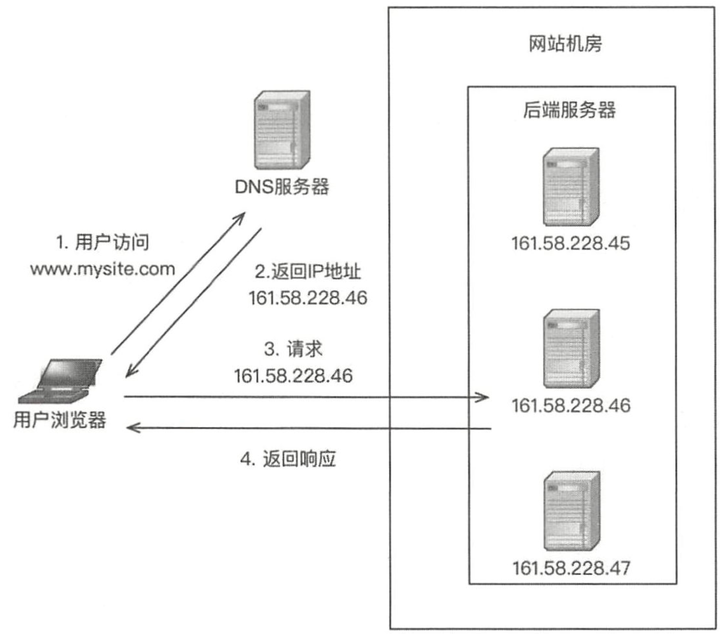
优点:1)简单,低成本;2)就近访问,可以提升访问速度
缺点:
1) 更新不及时,由于缓存更新;
2) 扩展差;
3) 分配策略简单:只能简单按地区分配ip,不能判断服务状态负载情况来分配
HTTP-DNS:用 HTTP 协议实现一个私有的 DNS 系统
2) 硬件负载均衡
硬件负载均衡:通过单独的硬件设备来实现负载均衡功能,这类设备和路由器交换机类似, 可以理解为一个用于负载均衡的基础网络设备。
两款:F5和A10
功能、性能、稳定性都很好,还有安全防护,就是很贵
3) 软件负载均衡
Nginx 和 LVS等利用软件实现负载均衡。


5.2.2 负载均衡架构
可以三种结合:域名解析,然后地区内,再到机房内可以不同层级的负载均衡
5.2.3 负载均衡的算法
1) 轮询:只简单轮询
2) 加权轮询:根据性能按比例分配
3) 负载最低优先:按qps,cpu等负载进行分配
4) 性能最优优先:性能强劲的机器优先分配
5) Hash:按ip,用户ID等hash分配
【第3部分】 高可用架构模式
第6章 CAP
6.1 CAP理论
第一版:


第二版:


6.1.1 一致性(Consistency)
第一版:


第二版:


第一版:从节点看数据一致;第二版:从客户端读的角度看数据一致。第二版更佳符合时间应用
6.1.2 可用性
第一版:


第二版:


第二版更加合理,强调非故障节点,没有错误和超时情况下返回合理的响应
6.1.3 分区容忍性(Partition Tolerance)
第一版:


第二版:


6.2 CAP应用
在分布式系统中,P(分区容忍)必须选择,网络本身无法做到100%可靠。
6.2.1 CP—Consistency/Partition Tolerance
CP:一致性+分区容忍性
如果要求一致性,节点之间相互访问失败,则返回错误,就不能保证可用性
6.2.2 AP—Availability/Partition Tolerance
AP:可用性+分区容忍性
为了保证可用性,某节点读数据失败,则返回自己缓存的数据,这样就不能保证一致性。
6.3 CAP细节
1) CAP关注的粒度是数据, 而不是整个系统
2) CAP 是忽略网络延迟的
3) 正常运行情况下,不存在CP和AP的选择, 可以同时满足CA
4) 放弃并不等于什么都不做,需要为分区恢复后做准备
6.4 ACID、BASE
ACID: 是数据库事务完整性的理论
CAP: 是分布式系统设计理论,
BASE:是 CAP 理论中 AP 方案的延伸
6.4.1 ACID
ACID:数据库保证事务
1) Atomicity (原子性)
一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节 。事
务在执行过程中发生错误,会被回滚到事务开始前 的状态, 就像这个事务从来没有 执行过 一样。
2) Consistency (一致性)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏 。
3) Isolation (隔离性)
数据库允许多个并发事务同时对数据进行读写和修改的能力。隔离性可以防止多个事务并
发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级 别,包括读未提 交( Read uncommitted)、读提交( read committed)、可重复读( repeatable read)和串行化(Serializable)。
4) Durability (持久性)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
6.4.2 BASE
BASE 是 Basically Available (基本可用)、 Soft State (软状态)和 Eventually Consistency (最终一致性〉三个短语的缩写 , 其核心思想是即使无法做到强一致性( CAP的一致性就是强一致性),但可以采用适合的方式达到最终一致性 (Eventual Consistency)。
1) 基本可用(Basically Available)
分布式系统在出现故障时,允许损失部分可用性,即保证核心可用 。
2) 软状态(Soft State)
允许系统存在中间状态,而该中间状态不会影响系统整体可用性 。这里的中间状态就是 CAP 理论中的数据不 一致
3) 最终一致性(Eventual Consistency)
系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
第7章 FMEA
FMEA (Failure mode and effects analysis,故障模式与影响分析)又称为失效模式与后果分 析、失效模式与效应分析、故障模式与后果分析等。FMEA 通过对系统范围内潜在的故障模式加以分析,并按照严重程度进行分类,以确定失效对于系统的最终影响。
7.1 FMEA介绍
FMEA分析方法:


7.2 FMEA方法
1) 功能点
登录/注册等
2) 故障模式
故障点和故障形式:比如mysql读取耗时特别大,具体是磁盘、内存等
3) 故障影响
比如:注册登录变慢2s等
4) 严重程度
业务角度影响程度,例如:


5) 故障原因
某个子模块出问题的具体原因:比如低版本bug等
6) 故障概率
硬件:超过N年后故障率升高;开源软件:维护力度不同bug率不同;自研系统:新老系统故障率不同
7) 风险程度
严重程度*故障率
8) 已有措施
检查告警:自动告警
容错:出问题切换副本等
自恢复:系统自动恢复
9) 规避措施
数据备份
网络双入口;双供电
为了减少异常,合适的时间自动重启
10) 解决措施
防止无线重试:限制重试次数
防止拖库:密码加密存储
访问权限:白名单控制敏感权限
11) 后续规划
对于不足的处理:备份,双机房,供电保证防止掉电数据丢失等
7.3 FMEA实战

第8章 存储高可用
高可用存储架构:1)主备、2)主从、3)主主、4)集群、5)分区
8.1 主备复制


主备:读写都从主节点,故障后人工切换到备用节点。简单,但是需要人工切换。对于频率不高的系统比较合适(学生管理/图书管理,等并发小的系统)
8.2 主从复制

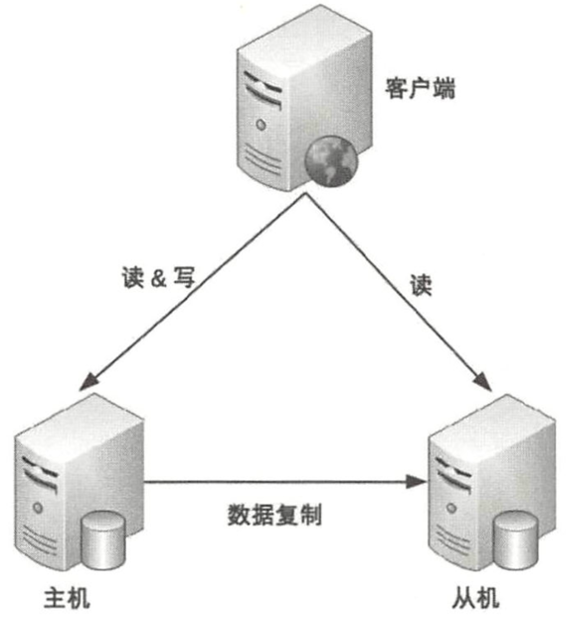
主从复制:
主节点:可写可读
从节点:只读。
主节点故障时,从节点继续可读,如果主节点不可恢复,人工进行主从切换。
适合读多写少的系统,比如:新闻,BBS博客类等
8.3 主备倒换与主从倒换
检查主节点、切换策略(断开多久?),主从切换(自动切换,主从倒换)
互连:主备节点两者相互通信
中介:主备节点都上报状态到中介服务,检查状态,判断主故障
模拟:从节点将写操作透传给主节点
8.4 主主复制
主主复制:两个节点都可读写,相互复制数据。
8.5 数据集群
集群:一批机器处理。分为:数据集中集群、数据分散集群
8.5.1 数据集中集群
所有数据都在一个集群,由主节点进行写入,复制给从节点;主节点失效后重新选举新的主节点
8.5.2 数据分散集群
数据按分类分布到不同机器,比如账号,联系人等
8.5.3 分布式事务算法
1) 2PC(Two-phase commit protocol)
2阶段提交:2PC:1)commit 请求阶段;2)commit 执行阶段。
2PC基于假设:


第一阶段:提交请求阶段(投票阶段)

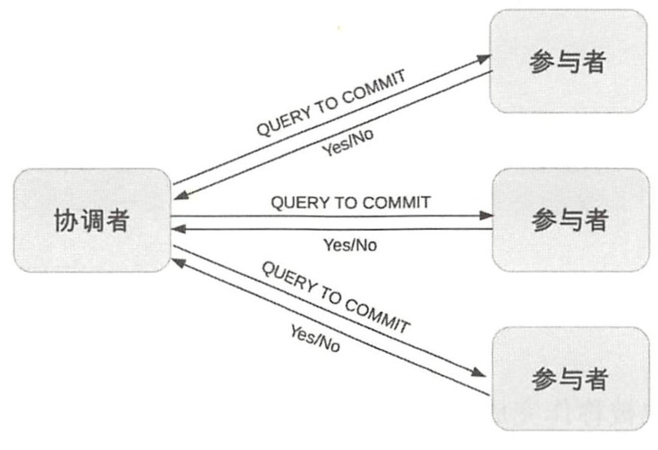


简单来说:协调者发起请求;参与者执行,执行成功返回Yes,执行失败返回No
第二阶段:提交执行阶段(完成阶段)

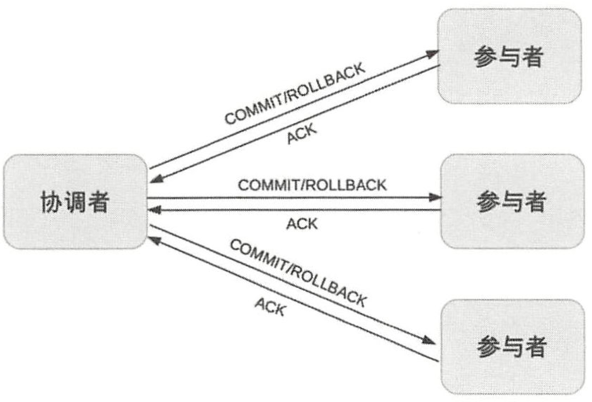
【成功】
当协调者从所有参与者获得的相应消息都为“ Yes”时 :


投票成功,开始提交执行,执行完成ACK确认,最后完成事务
【失败】
第一阶段参与者在第一阶段返回的响应消息为“No气或者协调者在第一阶段的询问超时之
前无法获取所有参与者的响应消息时 :


投票有一个失败,开始提交回滚,回滚完成ACK确认,取消事务
如果参与者没有收到执行请求,超时后也会自动回滚
2PC实现简单,缺点:


2) 3PC(Three-phase commit protocol)
3PC主要解决2PC单点问题:第一和第二阶段之间插入一个”准备阶段“

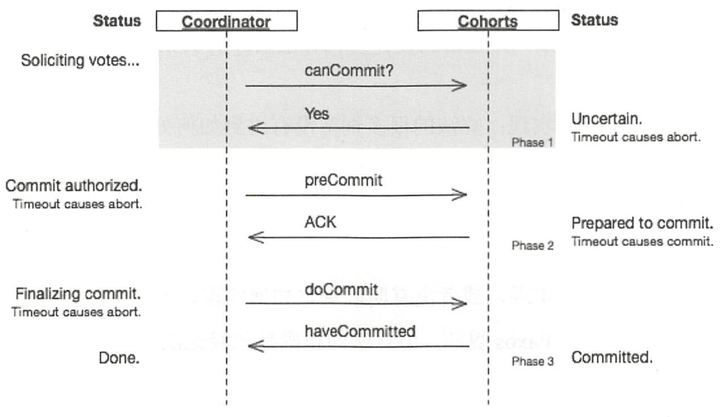
第一阶段(提交判断阶段):


第二阶段(准备提交阶段):


第三阶段(提交执行阶段):


8.5.4 分布式一致性算法
分布式事务算法:为了保证分散在多个节点上的数据统一提交或回滚,以满足ACID的要求;
分布式一致性算法:为了保证同一份数据在多个节点上的一致性;
1) Paxos


2) Raft


3) ZAB


8.6 数据分区
将数据按一定规则分区,存储在不同地区,一部分故障,不影响其他地区。
8.6.1 数据量
数据量的大小直接决定了分区的规则复杂度。例如,使用 MySQL 来存储数据,假设一台 MySQL 存储能力是500GB,那么 2TB 的数据就至少需要 4 台 MySQL 服务器;而如果数据是 200TB,并不是增加到 800 台的 MySQL 服务器那么简单。
8.6.2 分区规则
洲际分区、国家分区,城市分区
8.6.3 复制规则
集中式:所有节点从一个节点集中复制

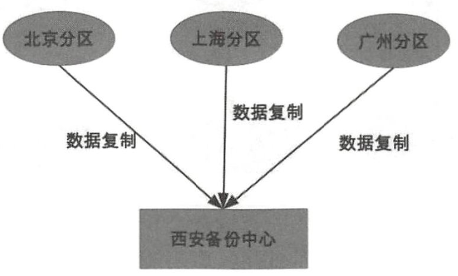
互备式:两两互相备份

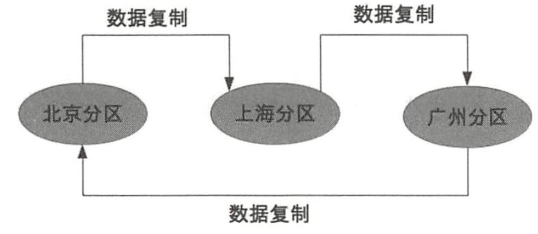
独立式:就近独立备份

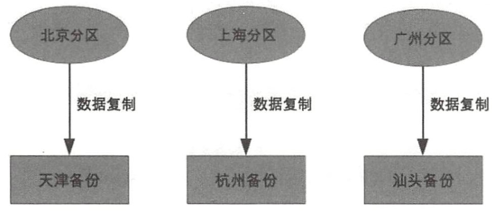
第9章 计算高可用
计算高可用:部分硬件损坏,计算任务依旧能执行
9.1 主备
主机:读写
从机:当主机故障时,将任务分配给从机
冷备:备机上程序配置都在,只是不启动服务,切换时需要先启动再切换流量过来
温备份:程序服务就绪状态,只是空跑,切换备份时直接切流量来即可。
9.2 主从
将任务按特征分配给主从机器,比如:主可读写,从只读。
9.3 对称集群
每个节点都对等可以执行每个任务,利用负载均衡来分配任务。
9.4 非对称集群
不同节点执行不同任务:比如登陆服务、下单服务,够买VIP服务。
文章来源于互联网:从零开始学架构(上篇)

