
Go 并发系列是根据我对晁岳攀老师的《Go 并发编程实战课》的吸收和理解整理而成,如有偏差,欢迎指正~
WaitGroup 是什么?
WaitGroup 是 Go 内置的 sync 包解决任务编排的并发原语。WaitGroup 直译是“等待组”,翻译成大白话就是等待一组协程完成任务。如果没有完成,就阻塞。
举个例子,我们要计算100万个数的和,并对这个和求根号。常规的思路肯定是先一个 for 循环计算总和,再开根号,但是这样效率很低。我们可以起1000个协程,每个协程计算1000个数的和,然后再对这些和求和,最后再开个根号。
这里有一个问题,计算根号的时候,需要等所有并发的协程都计算完才行,WaitGroup 就是解决等所有并发协程完成计算的问题的。
WaitGroup 的基本用法
WaitGroup 的用法很简单。标准库中的 WaitGroup 只有三个方法,分别是:
- Add:用来设置 WaitGroup 的计数值,delta 可正可负。
- Done:用来将 WaitGroup 的计数值减一,其实就是调用了 Add(-1)。
- Wait:阻塞等待,直到 WaitGroup 的计数值变成0,进入下一步。
WaitGroup 的使用套路
使用 WaitGroup 的常规套路如下:
- 声明 WaitGroup 变量
- 执行 Add 方法。协程组的个数有 n 个,执行 Add(n)
- 协程组中,每个协程最后,执行方法 Done
- 在协程组后面,执行 Wait 方法
拿上面那个计算100万个数之和再开根号的场景做示例:
为了图省事,我这里直接计算的使1-1000000的和。我们一起来看下这段代码。
第24行,先声明一个零值的 WaitGroup 变量。
第27行,因为这里开了1000个协程,所以执行 Add(1000)。
第28-30行,就是具体求和的部分。这里开了1000个协程求和,每个协程执行结束最后都会执行一次 Done() 函数,表示当前协程完成。
第31行执行 Wait() 函数,等待这1000个协程组完成任务。
看,WaitGroup 的使用确实很简单吧~~
WaitGroup 的实现原理
其实看完 WaitGroup 的使用示例后,我们就能大概猜到 WaitGroup 内部的实现原理:内部维护一个计数器,协程组中每完成一个任务,计数器减一,Wait() 函数中判断计数器的值是不是0,不是0的话,就阻塞,是的话,就进入下一步。
但是真的这么简单吗?
WaitGroup 的定义
先看下源码中 WaitGroup 的定义:
先解释一下 noCopy 这个变量。其实这个变量和 WaitGroup 的实际功能没有一毛钱关系。它的实际作用是用来检测是否存在复制 WaitGroup 的情况。
还记得之前提过的 go vet 工具吗?这个工具可以检测并发原语有没有被复制,原理是对 Locker 接口进行静态检查。
noCopy 实现了 Locker 接口:
所以通过 noCopy 这个变量,WaitGroup 也能被检查出来有没有被复制。
重点来了!!下面开始 state1 字段的解释!!
state1 不太好解释,所以我先把原始的英文注释放出来了,如果看不懂我解释的,就看注释吧。。。
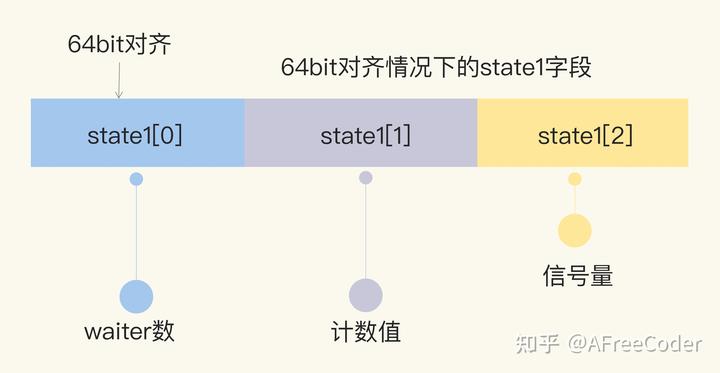
state1 是一个长度为3的 int32 类型的数组,在64位系统下定义如下:

在32位系统下,如果 state1 不是64位对齐,定义如下:

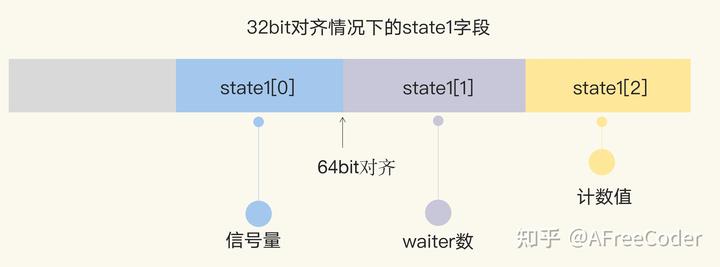
注意,32位系统中如果 state1 是64位对齐,还是使用上面的那种分配方式。
先不管是32位系统还是64位系统,总之我们能看到,不考虑顺序,state1 的3个元素分别表示【waiter数】,【计数值】和【信号量】。这三个元素不解释你也能大概猜出来是什么意思,计数值就是协程组中运行着的协程的个数,waiter 是等待者的个数,因为一般只执行一次 Wait 函数,所以 waiter 数一般是1。这一步没有任何问题。
那为什么要区分64位系统还是32位系统呢?
这里有一个知识点:64位的原子操作需要64位对齐【手动加粗】。
在后面 Add 或者 Wait 的操作中,类似这样的操作: atomic.AddUint64(statep, uint64(delta) 都是64位的原子操作,意思是说这个加法是对64位的内存块直接操作的。所以像这种64位的原子操作,都要求64位对齐。
64位对齐是要求数据的起始地址是64的倍数。在64位的系统中没有问题,但是在32位的系统中,内存块最小是4个字节,只能保证32位对齐,有可能会出现 state1 的起始地址不是64的倍数,而是32的倍数,这种情况下,将 state1[0] 当成信号量,就能保证 state1[1-2] 是64位对齐。
Add 和 Done 实现逻辑
Add 实现源码(删减了部分异常校验的逻辑):
一直到第8行之前,Add 部分的代码都很容易理解。获取 state 字段,拆成计数器和 waiter。delta 是多少,计数器就加多少。如果计数器的值大于0(其它协程已经执行了Add操作)或者 waiter 等于0(第一个 Add 操作),就直接进行下一步。
接下来的部分其实是执行 Done 之后的逻辑。看21-24行,Done 的实现就是 Add(-1)。
如果计数器等于0且 waiter 不等于0,说明这个时候需要唤醒 waiter 了。waiter 就是执行 Wait 然后阻塞的协程。
Wait 实现逻辑
Wait 的实现源码:
Wait 的逻辑也比较简单,如果计数器的值等于0,说明没有协程组的任务已经完成了,这个时候可以直接退出,继续执行后面的逻辑。如果计数器不等于0,就将 waiter 的数量加1,然后进入阻塞状态,等待被唤醒。
常规的用法中,我们只会调用一次 Wait,所以 waiter 的值就是1。其实如果有多个协程等待协程组的结果,也可以多次调用 Wait 函数。
WaitGroup 的易错场景
WaitGroup 的使用很简单,但是如果对 WaitGroup 的检查机制不清楚,误用了 WaitGroup,就会出现很多严重的问题。
下面让我们一起来看一下几种常见的错误场景。
问题一:计数器为负值
WaitGroup 的计数器的值必须大于等于0,不然就会出现 panic 错误。
一般情况下有两种场景会导致 WaitGroup 的计数器是负值。
一种是通过 Add() 函数直接将计数器设置为负值。比如上来就执行 Add(-1),程序会直接 panic,退出。这种情况比较简单,出错的可能性比较低。
另一种是 Done() 函数执行的太多,导致计数器变成负值。使用 WaitGroup 的正确方法是,首先确定 WaitGroup 的计数器的值(协程组的大小),然后调用相同次数的 Done()函数。如果 Done() 的调用次数过多,就会导致计数器的值为负,出现 panic。
当然,也不能少调用,否则会出现死锁。
问题二:不期望的 Add 时机
这个问题说的是所有 Add() 的执行需要确保在 Wait() 执行之前,否则,Add() 还没有执行,Wait() 先执行,判断出计数器值等于0,就直接进行下一步。
举个例子:
这段代码中,Add() 的执行就在每个最后,但是如果你复制一下这段代码,执行一下就会发现,终端不会打印任何字符。这是因为 Add() 还没来的及执行,计数器的值还是0,导致 Wait() 判断失误,程序提前结束。
修改的方法很简单,提前计算出有有多少个协程,然后在 for 循环前面一次性执行,或者在每个协程的一开始,也就是第10行前面,提前执行 Add(1)。
问题三:前一个 Wait() 还没有,就复用 WaitGroup
这个问题不太好理解。
首先 WaitGroup 是可以重用的。也就是说,只要 WaitGroup 的计数器的值变成0,那么它就可以看做是新创建的 WaitGroup,被重复使用。
但是重复使用前,一定要等之前的 Wait() 执行完毕,才能执行 Add() 或者
Done() 等函数,否则会报“不能重用的错误”。
比如下面这个例子:
这里虽然第6行将计数器置成了0,但是因为第9行的 Wait() 一直在循环检测,它就会和第7行的的 Add() 形成并发冲突。
所以,WaitGroup 虽然可以重用,但是必须等上一轮的 Wait() 执行完成之后,才能执行 Add()/Done() 等操作。否则,可能会出先 panic,提示 sync: WaitGroup is reused before previous Wait has returned。
原创不易,欢迎大家关注我的公众号【码农的自由之路】,左手代码,右手理财,996的码农也想自由~
都看到这里了,不如顺手点个 赞/喜欢?
有个奇怪的现象:技术类的文章收藏数远远高于评论数,但是有多少收藏之后会阅读呢?所以有问题大家尽管评论哈,我尽量解答~~
文章来源于互联网:Go 并发任务编排利器之 WaitGroup

