
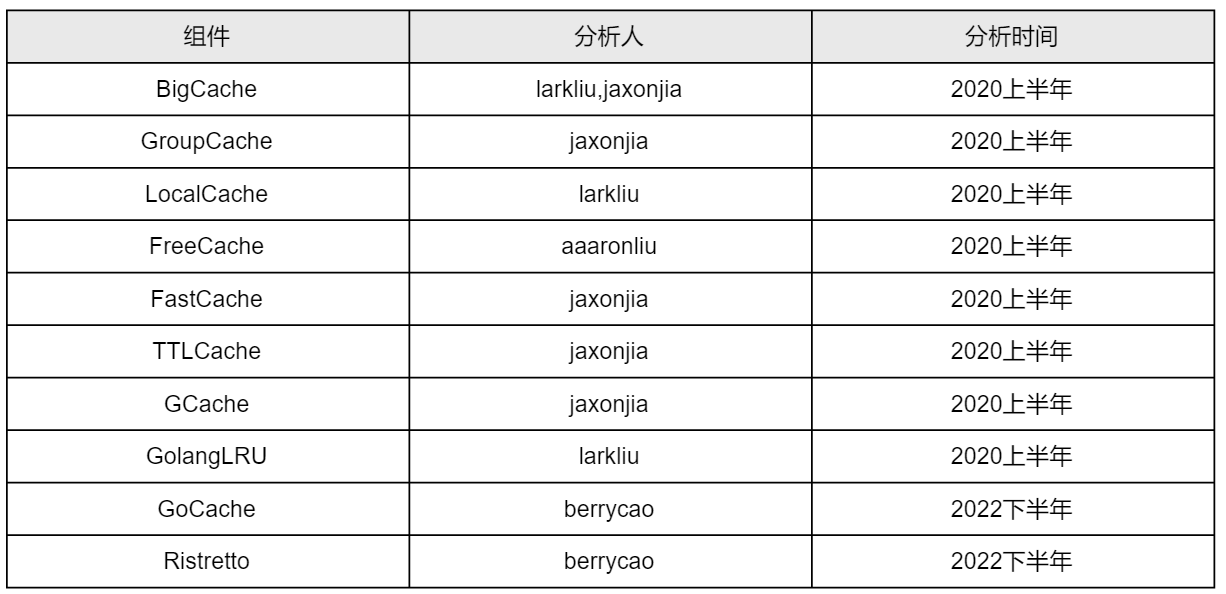
一个 Golang 自研小组件,分享一下研发过程。
作者:frank、maxy、lark 等。
从 2020 年团队转型 Golang 开始,团队内小伙伴在学习 Golang 的过程中,逐步积累了一些开源组件的使用经验,比如布隆过滤器、位图、localcache 等技术组件,结合业务场景,我们将这些开源组件集成起来,形成一套整体解决方案 TCache。
TCache
设计目标
视频会员场景下,部分产品功能来自 APP 的请求量非常大,如果直接透传到存储层,一方面对存储的性能要求会比较高,另一方面一旦请求异常升高,存储可能会成为性能瓶颈,引发故障。因此这里希望能够做适当缓存,减少底层存储的压力,提升系统可用性。
我们考察了业界开源的布隆过滤器、位图、localcache 等技术组件,发现相关组件非常多,同时各具特点,不同组件可能适合不同场景,
这促使我们将众多开源组件集成起来,形成一套整体解决方案,业务根据自身特点配置化选用不同底层组件,这是 TCache 的设计初衷。
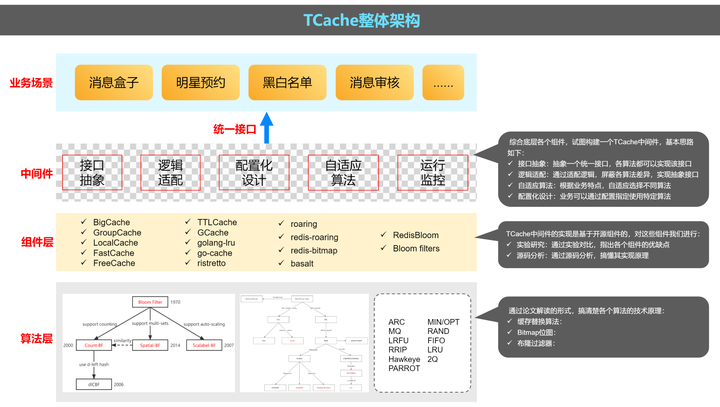
整体架构
✓ 最上层是一些用到 cache 的业务场景
✓ 中间件层:这层是 TCache 的核心部分,综合底层各个组件,试图构建一个 TCache 中间件,基本思路是抽象一个统一接口,各算法都可以实现该接口逻辑适配:通过适配逻辑,屏蔽各算法差异,实现抽象接口自适应算法:根据业务特点,自适应选择不同算法配置化设计:业务可以通过配置指定使用特定算法
✓ 组件层:TCache 中间件的实现是基于开源组件的,对这些组件我们进行实验研究:通过实验对比,指出各个组件的优缺点源码分析:通过源码分析,搞懂其实现原理
✓ 算法层:通过论文解读的形式,搞清楚各个算法的技术原理:缓存替换算法;Bitmap 位图;布隆过滤器。

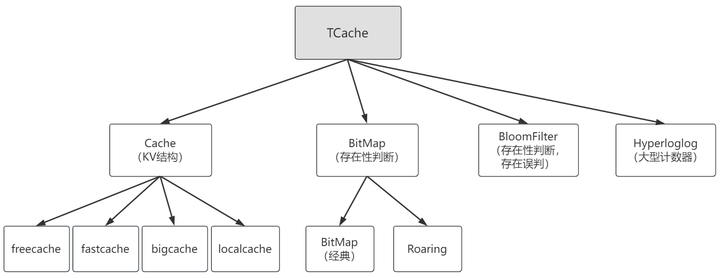
组件结构
整个 TCache 计划以下几类组件:
KV 型结构 Cache:已经集成 freecache,fastcache 和 bigcache,localcache
存在性判断 BitMap:计划集成 2 个开源组件,经典 bitmap 和 roaring
概率性判断 BloomFilter:暂未启
大型计数器 Hyperloglog:暂未启动

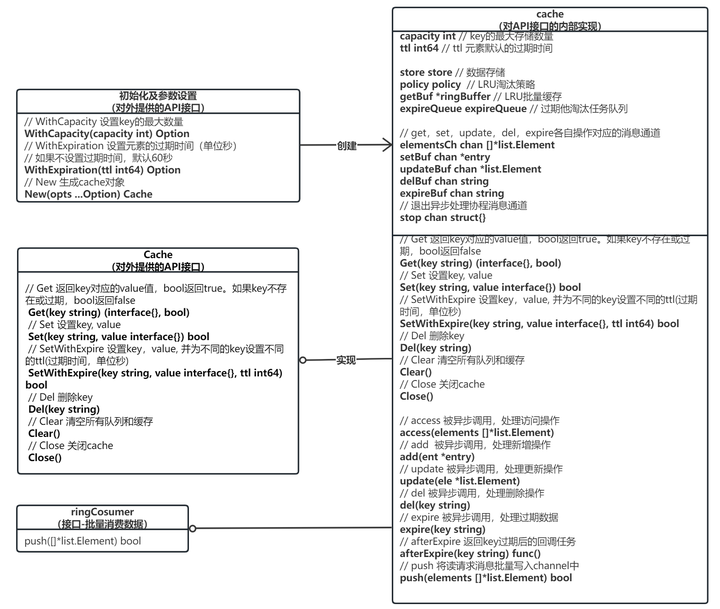
Cache 组件设计

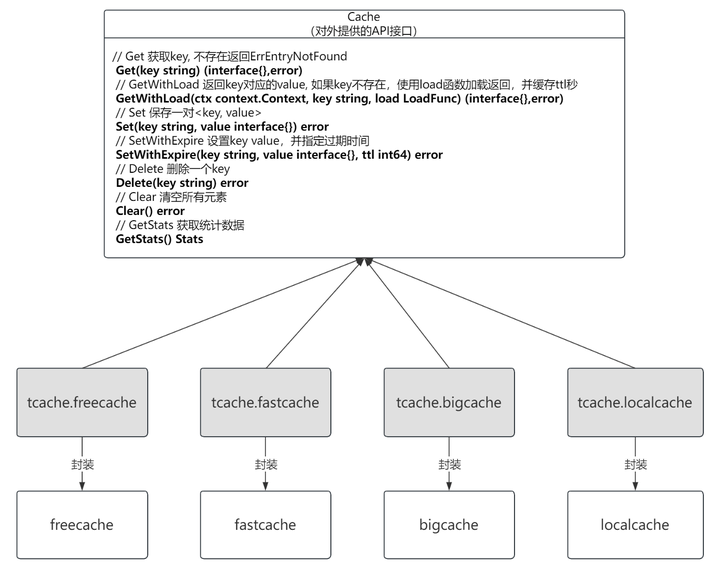
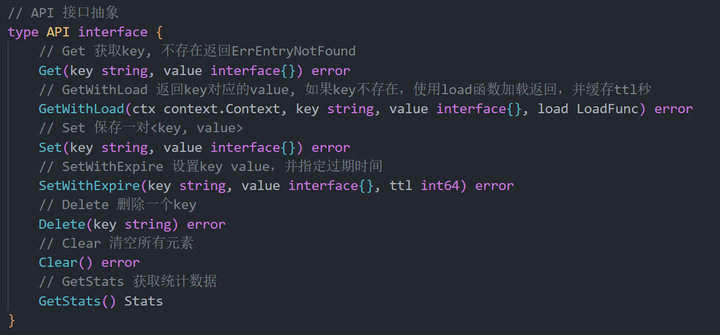
附:cache 接口定义

附:构造函数定义,用户可以通过 engine 指定底层 cache

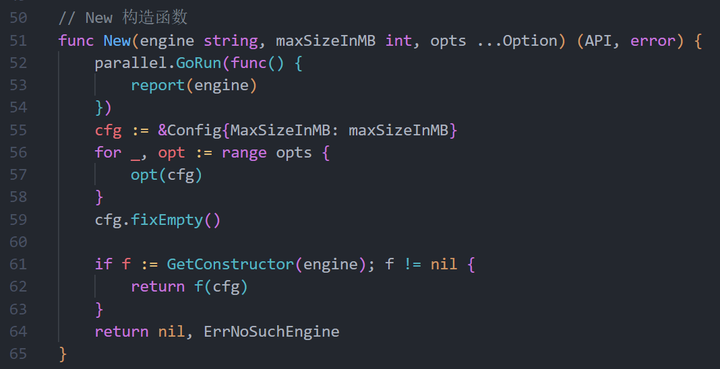
附:缺省实现,tcache 提供了一个缺省实现,默认使用 freecache

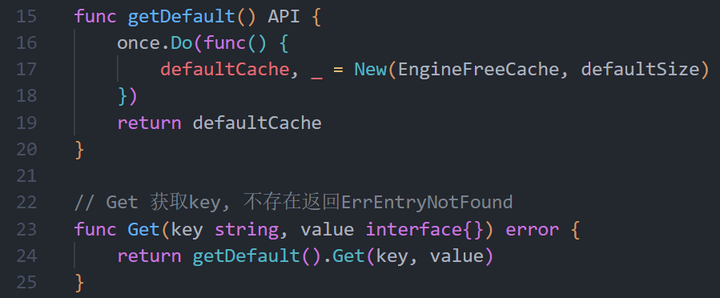
附:localcache 的接口定义

BitMap 组件设计
BitMap 虽不如 Cache 使用普遍,但也有一定使用场景,目前的开源组件有两条技术路线:
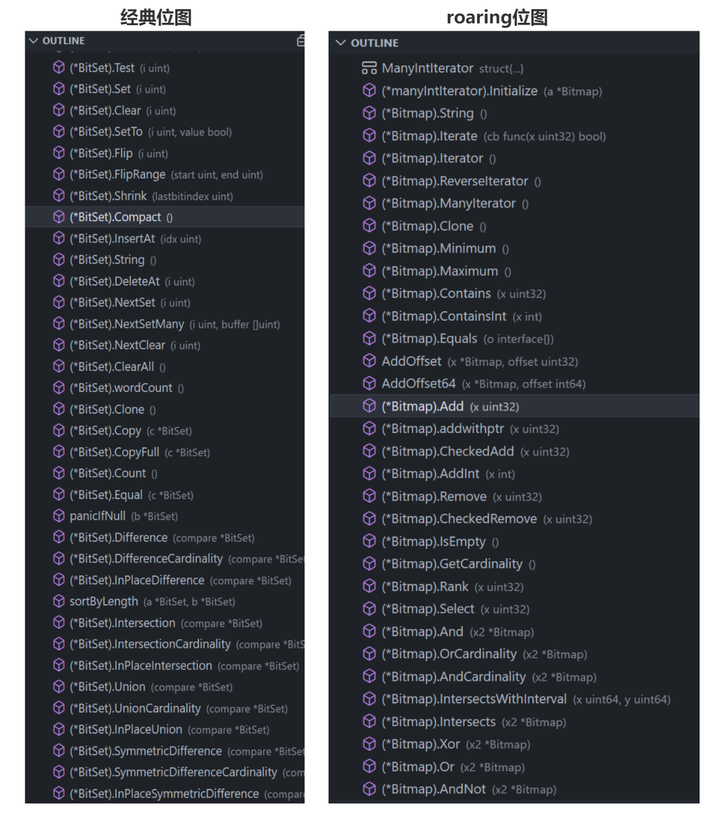
1) 经典 BitMap:这类算法一般都是在原始位图的基础上进行内存压缩,以减小内存空间
2) Roaring 位图:本质上是一种自适应算法,会动态的根据元素的大小和特征,选择[ArrayContainer,BitmapContainer,RunContainer]中的一种来表示。
为了便于使用,这个 API 仅限于对单个位图的操作,不涉及两个位图之间的集合操作。

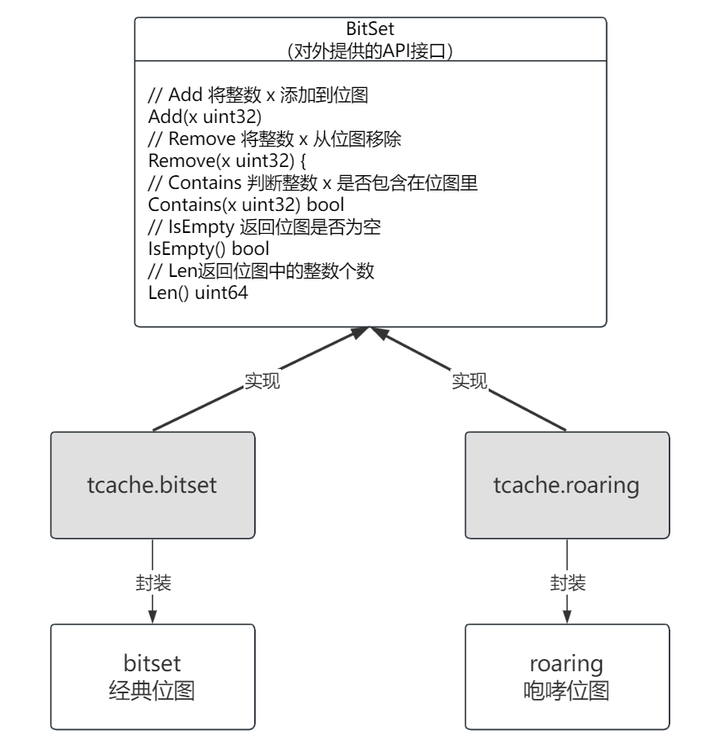
附:开源组件的实际接口

开发过程
做 tcache 的过程,其实是一个慢慢酝酿的过程,往前可以追溯到 19-20 年团队从 c++切换到 golang 语言,当时做了一个 cache 库的技术选型,然后我们知道业界已经有非常多的开源 cache 库,记得当时我们做了一些功能分析,还做了一些简单的性能对比。
在这之后,作为深入学习 golang 的方法之一,我开始带领团队分析这些开源组件的源码,一边读源码一边用 uml 做建模,陆陆续续几个同学把所有常见的组件分析了一遍。之所以分析源码,是因为我一直觉得阅读优秀源码是提高编码能力最快最有效的方法之一。
看完源码之后,发现只搞懂了这些开源组件的技术实现,里面的算法,别人为什么要那么设计,完全搞不懂。也就是说做完了源码分析,只做到了知其然不知其所以然,然后我们开始找这些算法背后的论文,然后开始研读,慢慢积累了一些读书笔记并发了几篇 km 文章。
看技术论文的过程中,发现几乎所有论文都会对不同算法进行对比分析,用以说明自己算法的优点。受这种思路的启发,我们也建立了一个研究框架,将我们研究过的所有开源组件,从功能和性能两方面多个维度做对比研究,从整体上呈现出各个组件的技术特点。
然后是组件化。22 年下半年部门发起了技术立项,然后我们发起了 TCache 项目,将业界常用的缓存组件集成起来,业务可以根据其特点选择不同算法。
功能分析
本地缓存可认为是一个基于本地内存的 KV 数据库,相比一般的存储系统,本地缓存对数据一致性的要求相对宽松,常用于缓存一段时间内不太变化的数据。一个优秀的本地缓存组件一般需要具有如下特点:
✓ 线程安全:支持并发访问,在多线程场景下,能处理并发读写等数据竞争问题。
✓ 高命中率:支持数据过期淘汰,能够适应一些非随机的数据访问规律,缓存热点数据。
✓ 高吞吐量:避免系统长时间 GC,导致实际性能下降。
✓ 支持内存限制:限制内存使用量,避免 OOM 影响本身业务。
目前常见的 golang 本地缓存组件有:

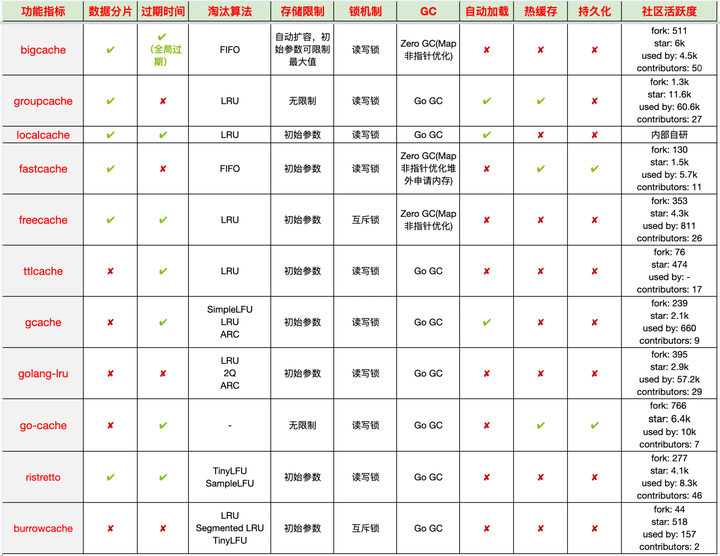
● 本地缓存组件核心技术点:设置缓存容量,限制内存大小,避免 OOM
✓ key 哈希后数据分片,缩小锁粒度
✓ 优化 key 哈希算法,减少碰撞
✓ 实现 singleflight 机制,避免缓存穿透
✓ 优化索引和数据的存储结构,规避 Go GC,提高吞吐量
✓ 跟踪和统计缓存访问记录,实现多种缓存替换策略,提高缓存命中率
✓ 自定义缓存回调函数,可以在 key 加载、过期、删除时做一些处理
✓ 持久化和热加载,处理缓存冷启动问题
源码分析
作为学习 golang 的一部分,开始研究一些经典 cache 开源组件,一边读源码一边用 uml 做建模。下面是几个例子。
✧ 例子:BigCache
根据对 BigCache 实现原理的深入分析,BigCache 最适合缓存图片、软件制品、文本以及任何二进制数据,这些数据一经生成则很少修改。BigCache 支持数据过期但不支持 LRU,本质上是一种先进先出。
基本原理:

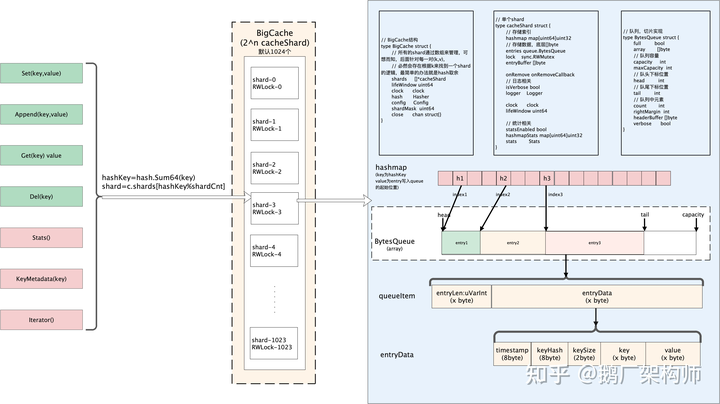
核心数据结构:

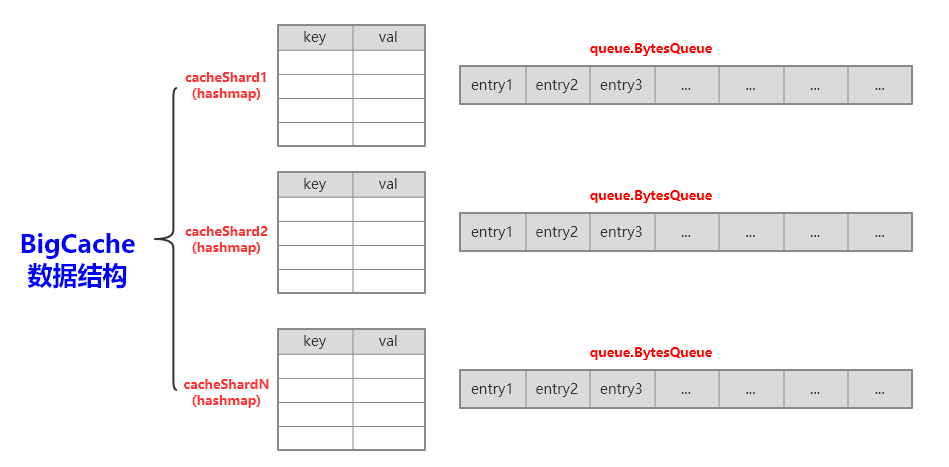

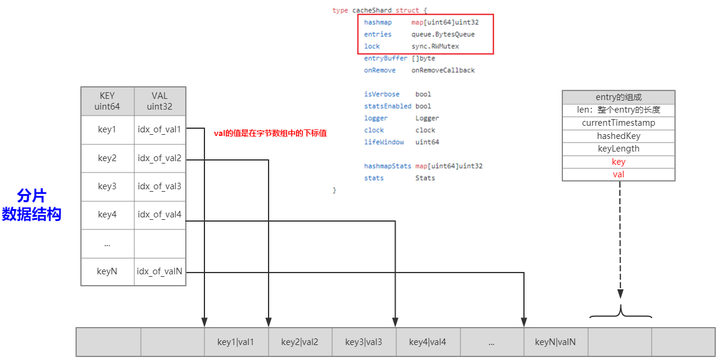
以上只是 BigCache 的例子,全部组件参见:Cache 组件源码分析

✧ 例子:BloomFilter
核心数据结构:

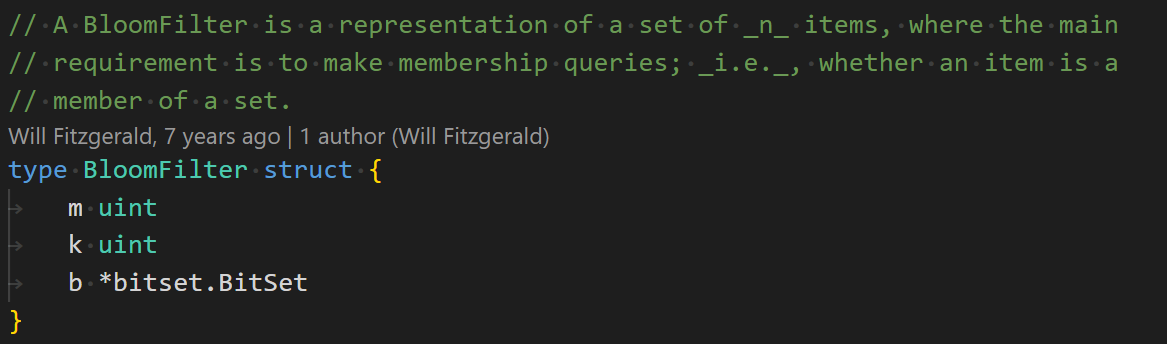
字段含义:
● m:底层 bitmap 长度
● k:哈希函数个数
● b:底层存储的 bitmap
内存使用:
| 结构体 | 字段 | 大小(字节) |
|---|---|---|
| BloomFilter | m:uint | 4 |
| k:uint | 4 | |
| b:bitset.Bitset | 4 | |
| Bitset | length:int | 4 |
| set:[]uint64 | 8*⌈length/64⌉ |
更多内容参见:BloomFilter-Golang 源码分析,pishi
✧ 例子:RoaringBitmap
核心数据结构:

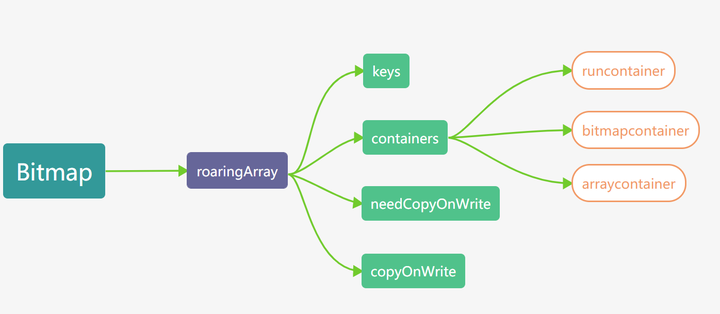

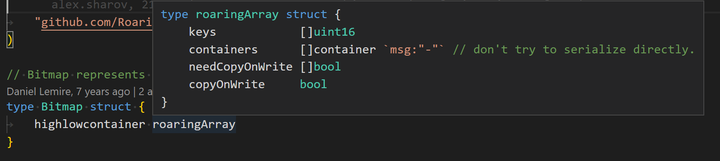
字段含义:
● highlowcontainer:包装了底层存储 bitmap 的数据结构
roaringArray:
字段含义:
● keys:与 containers 和 needCopyOnWrite 配合使用,作为一个 map。key 值对应的是一个 int 的高 16 位,以升序排列
● containers:与 keys 配合使用,作为一个容器 map。value 值对应的是对应的 container 类型,可以是 arraycontainer、bitcontainer 和 runcontainer 中的一种
● needCopyOnWrite:与 keys 配合使用,作为一个标记 map。value 值标记在 container 写入时,是否需要拷贝
● copyOnWrite:全局标记,container 写入时是否拷贝
container:

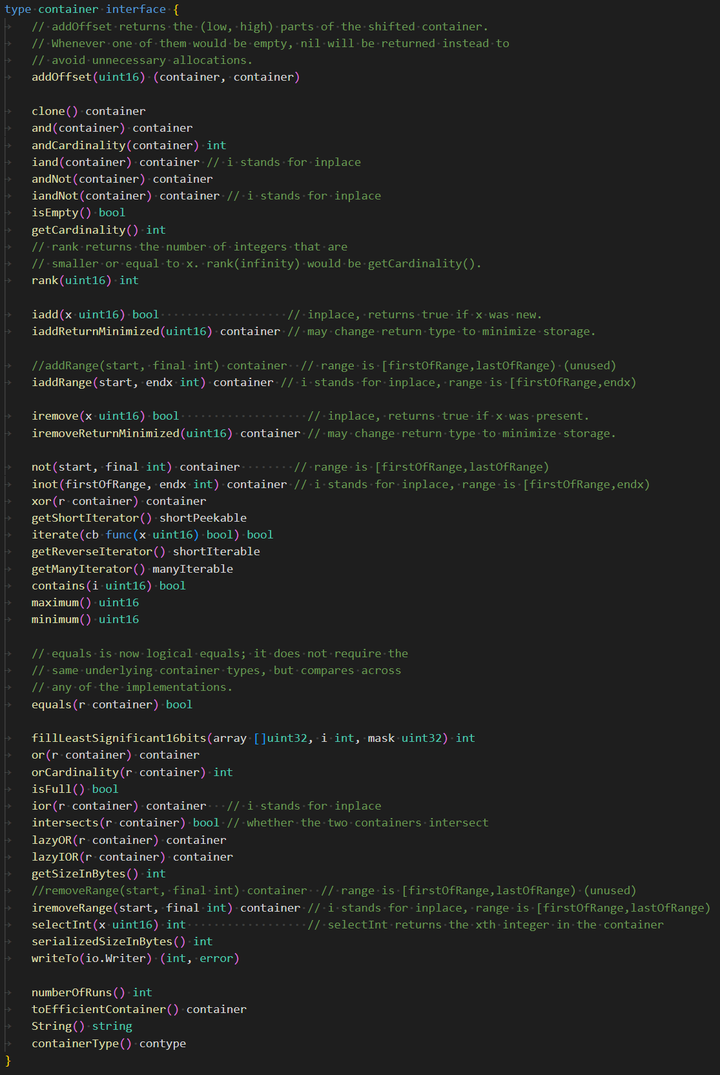
内存使用:
| 结构体 | 字段 | 大小(字节) |
|---|---|---|
| Bitmap | highlowcontainer:roaringArray | sizeOf(roaringArray) |
| roaringArray | keys:[]uint16 | 2*key 个数 |
| containers:[]container | sizeOf(containers) | |
| needCopyOnWrite:[]bool | 1*key 个数 | |
| copyOnWrite:bool | 1 | |
| arrayContainer | content:[]uint16 | 2*元素数量 |
| bitmapContainer | cardinality:int | 4 |
| bitmap:[]uint64 | 2^13 | |
| runContainer16 | iv:[]interval16 | 4*runs 长度 |
| interval16 | start:uint16 | 2 |
| length:uint16 | 2 |
更多内容参见:RoaringBitmap-Golang 源码分析,pishi
算法研究
研究完源码后,发现知其然不知其所以然,然后开始找论文,研究背后的算法。
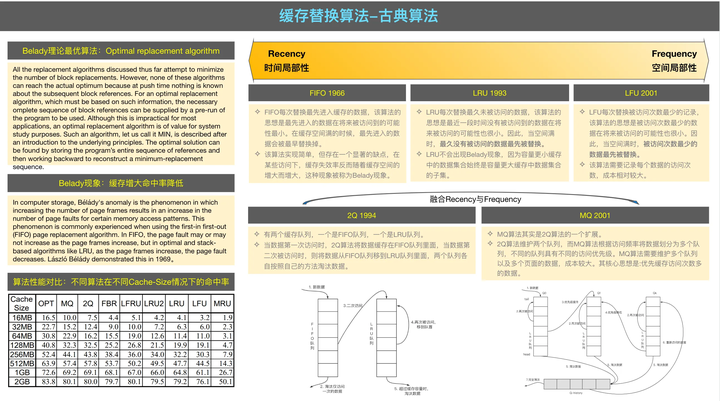
✧ 常见的缓存替换算法从策略上大致有以下几种:
➢ Belady 最优策略
缓存替换的最优算法(MIN/OPT,Optimal)在 1966 年由 Laszlo A.Belady 提出,此算法在已知未来所有访问记录的前提下,每次都替换未来不再被访问/最远被访问的现存数据。该算法是理论上的最优算法,因为需要已知未来所有访问记录,并不具备可实现性,通常用于衡量其它缓存替换算法的优劣。
➢ 随机替换策略
随机替换算法(RAND,Random)从现存数据中随机选择一个元素进行替换,该算法不需要维护历史访问记录的任何信息,实现上简单高效,但命中率通常一般。
➢ 简单排队策略
先进先出算法(FIFO,First In First Out)每次替换最先进入缓存的数据,该算法认为最先进入的数据在将来被访问到的可能性最小。FIFO 算法存在 Belady 现象:在某些情况下,缓存容量增大命中率反而降低。
➢ 最近不使用策略
最近最少使用算法(LRU,Least Recently Used)每次替换最久未被访问的数据,该算法认为最近一段时间没有被访问到的数据在将来被访问的可能性最小,这种策略在实际中应用较广。
➢ 最不经常使用策略
最近最不常用算法(LFU,Least Frequently Used)每次替换访问次数最小的数据,该算法的思想是最近一段时间被访问次数最小的数据在将来被访问的可能性最小。
➢ 重引用间隔预测策略
重引用间隔预测算法(RRIP,Re-Reference Interval Prediction)使用 M bits 来存储每个数据的 RRPV 值,RRPV 值随着每个数据被访问的频率动态变化,每次替换 RRPV 值等于的数据。
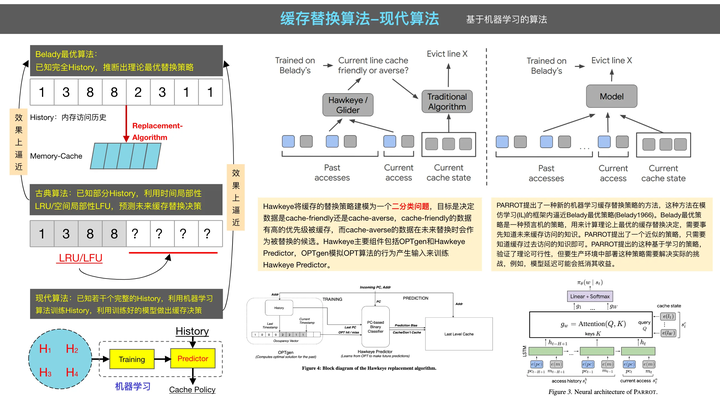
➢ 近似 Belady 最优策略
Hawkeye 算法通过使用过去的访问记录来模拟 OPT 算法的行为产生输入来训练 Hawkeye Predictor,再基于 Predictor 做决策。
➢ 机器学习策略
PARROT 算法将缓存替换任务建模为强化学习任务,目标是找到能使长期累积奖赏最大化的缓存替换策略。
上面对缓存替换算法进行了简要介绍,技术上它们可分为基于经验规则的古典算法和基于机器学习的现代算法。古典算法是人类基于直观经验,对一些数据访问模式人工总结经验而设计得到的一类算法,如 RAND、FIFO、LRU、LFU、2Q、MQ、ARC、LRFU、RRIP 等。古典算法主要是基于数据的最近访问时间(Recency)或访问频率(Frequency)平衡策略,算法模型和实现相对简单,实际应用较广。现代算法是将缓存替换建模成机器学习任务,基于历史访问记录,利用机器学习技术训练模型,使用习得的模型决策淘汰哪个缓存元素的一类算法,如 Hawkeye、PARROT 等。现代算法的模型和实现相对复杂,目前还处在实验研究阶段。




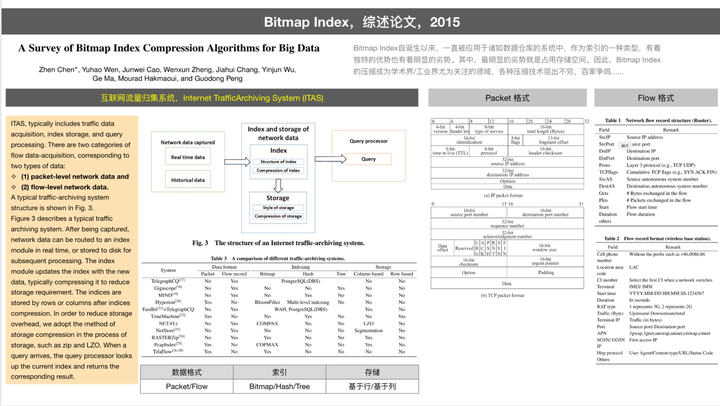
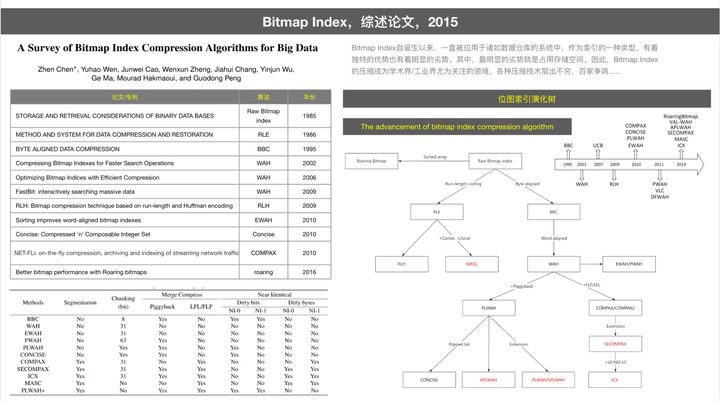
✧ 位图算法,以下是一个相关位图算法的综述
2015 年清华大学团队以互联网流量归集系统(Internet Traffic-Achival System,ITAS)为研究场景,以 ITAS 中的重要组成部分索引存储和压缩为重点,综述了位图索引压缩技术。论文中虽然对不同的位图索引压缩技术做了总结,但并未进一步深入其算法原理。因此,本文将从细节的算法方面,对位图索引压缩技术做进一步综述。




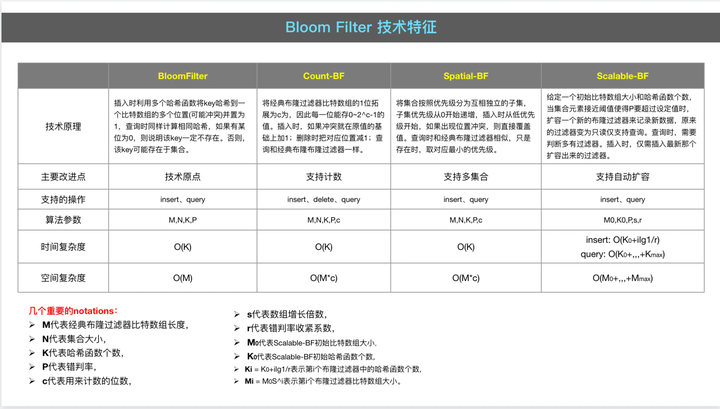
✧ 布隆过滤器,演进关系与技术特征



实验研究
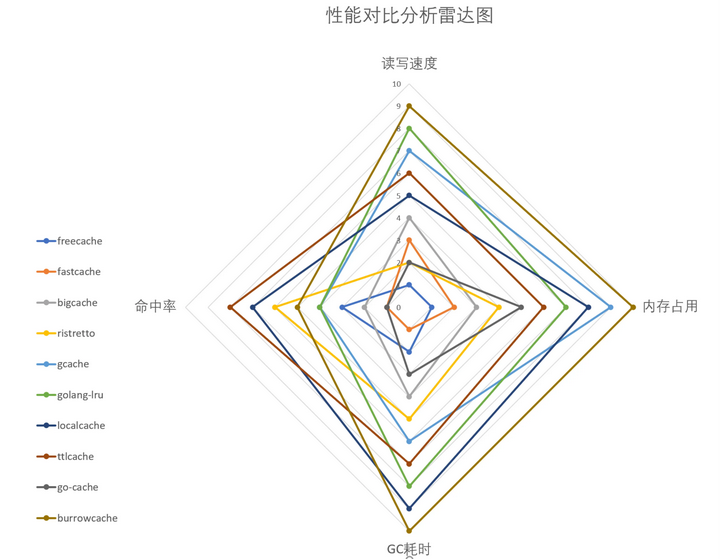
参考学术论文的方法,我们也建立了一个研究框架,从功能和性能两方面多个维度做对比研究,主要的研究结论如下:
1) 对于整体业务数据量不是很大的高并发场景,推荐使用 freecache(PS:freecache 内存是根据初始参数预先分配好的,可能会浪费内存)
2) 对于数据量大、高并发,所有数据可共用一个全局的过期时间(比如都是写入 60s 后过期)的场景,推荐使用 bigcache(PS:bigcache 仅预先分配少量内存,后续动态扩容)。
3) 对于数据不需要定时过期,且后续需要持久化到磁盘,单个缓存数据都小于 64KB,高并发的场景,推荐使用 fastcache。
4) 对于可以接受数据写入可能延迟(Set 之后立刻去取可能取不到,Delete 之后可能还会读到),读多写少的场景,推荐使用 localcache。(PS:localcache 是内部自研组件)
5) 对于可以接受 Set 操作不保证成功,对缓存 key 的价值有清晰认识,数据访问模式符合 LFU 策略的场景,推荐尝试一下 ristretto。(PS:在本文的各基准数据集上 ristretto 命中率并不高,可能是 config 设置和 cost 传值不合适,需要更多探索)
6) 对于数据量小,业务并发量不高的场景,也可以使用 gcache(支持过期时间)和 golang-lru(不支持过期时间),这两个组件支持多种淘汰算法,其中 ARC 是一种自适应的缓存淘汰算法,是基于 Recency/Frequency 的平衡策略。
7) ttlcache、go-cache 和 burrowcache 不太推荐。go-cache 无法限制缓存容量,没有淘汰策略,历史数据会一直累积,有 OOM 的风险。



组件化
22 年下半年,部门内开始做一些技术立项,于是有了开头的 TCache 组件:
在构思 TCache 的时候,MySQL 的插件存储引擎体系,给了我们很大启发:

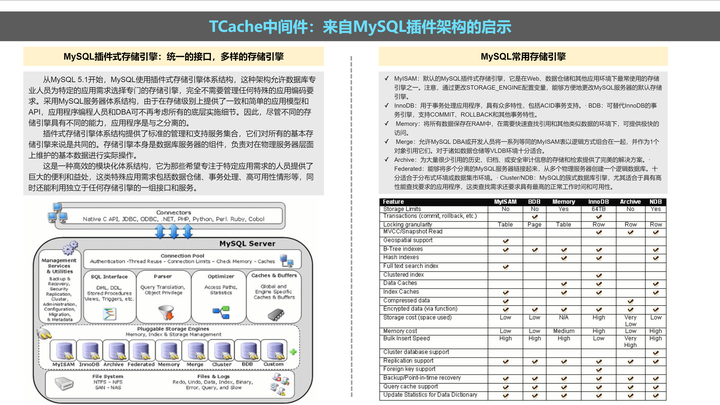
同样的,司内的开源项目 TRecall,其设计思路也给了我们很大启发:

总结一下
开发 TCache 组件,本身是一个无心插柳的过程,最后能够结出一个小果实,也是意外之举。
从结果来看,我们似乎找到一个既有理论深度又有技术深度的垂直切口深挖,在业务开发的空余间隙里,花时间慢慢沉淀,最终总算是开花结果,弄出一个小组件。
如何找到创新方向,既有技术上的长期积累,也需要积极思考业务场景中的公共技术需求,技术和场景找到交叉点就是创新。有时候可遇不可求。


TCache 只是一个微创新,但也是一个小的原创,写这篇文章只是介绍一下整个过程。
结合当下如火如荼的 AIGC、ChatGPT,如果也能利用业界的开源工具链,整合出一套原创组件并找到应用场景,比如 AI 辅助编程、借助 AI 将 UML 图转化为代码等等,那么很有可能颠覆我们这个开发行业。
文章来源于互联网:鹅厂微创新Golang缓存组件TCache介绍

