
Kafka是一种分布式消息系统,被广泛应用于数据传输、日志收集、实时处理等领域。在Kafka中,数据以消息的形式存储和传输,因此,保证消息的可靠性是非常重要的。本文将详细介绍如何保证Kafka不丢失消息,并给出一些实际案例。
生产者端配置
生产者是将消息发送到Kafka的一方,因此,生产者端的配置对于消息的可靠性非常重要。在生产者端,可以通过以下配置来保证消息的可靠性:
- acks配置:该配置指定了生产者接收到服务器确认消息的方式。默认值为1,表示只要Leader节点收到消息就认为发送成功,但是可能存在消息丢失的情况。如果将acks配置为-1或all,表示等待所有副本节点收到消息后才认为发送成功,这样可以保证消息不丢失,但是可能会影响发送性能。
- retries配置:该配置指定了生产者在发送消息失败后进行重试的次数。默认值为0,表示不进行重试。如果将retries配置为一个大于0的值,表示发送失败后进行重试,可以提高消息的可靠性,但是也会影响发送性能。
- batch.size配置:该配置指定了生产者将多个消息批量发送到Kafka的大小。默认值为16384字节。如果将batch.size设置为一个较大的值,可以减少发送请求的次数,提高发送性能,但是也可能会增加消息丢失的风险。
- max.in.flight.requests.per.connection配置:该配置指定了生产者在发送消息后等待服务器响应的最大请求数。默认值为5。如果将max.in.flight.requests.per.connection设置为一个较小的值,可以降低消息丢失的风险,但是也会影响发送性能。
先介绍一下生产者发送消息的一般流程(部分流程与具体配置项强相关,这里先忽略):
- 生产者是与 leader 直接交互,所以先从集群获取 topic 对应分区的 leader 元数据;
- 获取到 leader 分区元数据后直接将消息发给过去;
- Kafka Broker 对应的 leader 分区收到消息后写入文件持久化;
- Follower 拉取 Leader 消息与 Leader 的数据保持一致;
- Follower 消息拉取完毕需要给 Leader 回复 ACK 确认消息;
- Kafka Leader 和 Follower 分区同步完,Leader 分区会给生产者回复 ACK 确认消息。


生产者采用 push 模式将数据发布到 broker,每条消息追加到分区中,顺序写入磁盘。消息写入 Leader 后,Follower 是主动与 Leader 进行同步。
Kafka 消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过 producer.type 属性进行配置。
Kafka 通过配置 request.required.acks 属性来确认 Producer 的消息:
- 0:表示不进行消息接收是否成功的确认;不能保证消息是否发送成功,生成环境基本不会用。
- 1:默认值,表示当 Leader 接收成功时确认;只要 Leader 存活就可以保证不丢失,保证了吞吐量。所以默认的 producer 级别是 at least once。
- all:保证 leader 和 follower 不丢,但是如果网络拥塞,没有收到 ACK,会有重复发的问题。
如果 acks 配置为 0,发生网络抖动消息丢了,生产者不校验 ACK 自然就不知道丢了。
如果 acks 配置为 1 保证 leader 不丢,但是如果 leader 挂了,恰好选了一个没有 ACK 的 follower,那也丢了。
如果 acks 配置为 all 保证 leader 和 follower 不丢,但是如果网络拥塞,没有收到 ACK,会有重复发的问题。
通过合理配置生产者端的参数,可以有效地保证消息的可靠性。下面是一个示例:
bootstrap.servers=kafka01:9092,kafka02:9092,kafka03:9092
acks=all
retries=3
batch.size=32768
max.in.flight.requests.per.connection=1消费者端配置
消费者是从Kafka中读取消息的一方,因此,消费者端的配置对于消息的可靠性也非常重要。在消费者端,可以通过以下配置来保证消息的可靠性:
- auto.offset.reset配置:该配置指定了消费者在没有offset的情况下从哪里开始消费。默认值为latest,表示从最新的消息开始消费。如果将auto.offset.reset配置为earliest,表示从最早的消息开始消费,这样可以避免消息丢失,但是也可能会重复消费一些消息。
- enable.auto.commit配置:该配置指定了消费者
在消费者端,还可以使用以下方式来保证消息的可靠性:
- 手动提交offset:在默认情况下,Kafka会自动提交offset。但是,如果消费者在消费消息时发生故障,那么已经消费的消息可能会被重复消费。因此,可以使用手动提交offset的方式来保证消息的可靠性。手动提交offset可以使用commitSync方法和commitAsync方法,前者会阻塞线程等待提交结果,后者会异步提交,不会阻塞线程。
- 设置isolation.level为read_committed:在Kafka的高版本中,可以通过设置isolation.level为read_committed来保证只消费已经提交的消息。这样可以避免消费到未提交的消息,提高消息的可靠性。
消费者通过 pull 模式主动的去 kafka 集群拉取消息,与 producer 相同的是,消费者在拉取消息的时候也是找 leader 分区去拉取。
多个消费者可以组成一个消费者组(consumer group),每个消费者组都有一个组id。同一个消费者组的消费者可以消费同一 topic 下不同分区的数据,但是不会出现多个消费者消费同一分区的数据。

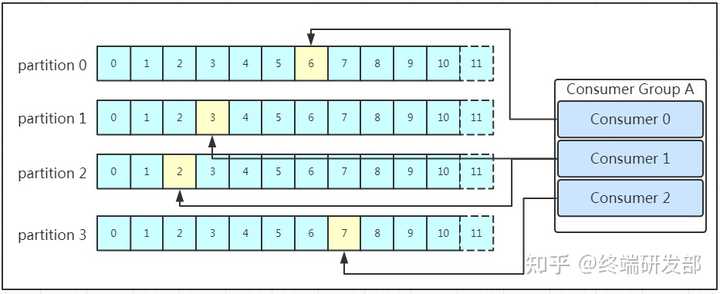
消费者消费的进度通过 offset 保存在 kafka 集群的 __consumer_offsets 这个 topic 中。
消费消息的时候主要分为两个阶段:
- 标识消息已被消费,commit offset坐标;
- 处理消息。
先 commit 再处理消息。如果在处理消息的时候异常了,但是 offset 已经提交了,这条消息对于该消费者来说就是丢失了,再也不会消费到了。
先处理消息再 commit。如果在 commit 之前发生异常,下次还会消费到该消息,重复消费的问题可以通过业务保证消息幂等性来解决。
副本机制
在Kafka中,每个Topic都可以配置多个Partition,并且每个Partition可以配置多个副本。每个Partition的副本会分布在不同的Broker上,以保证数据的冗余和高可用。副本机制可以在Broker节点发生故障时保证数据的可用性。
副本机制的实现是通过复制消息来实现的。当消息被发送到Kafka时,Kafka会将消息复制到每个Partition的副本中。每个副本都有一个Leader节点和多个Follower节点。当Leader节点出现故障时,Follower节点会选举一个新的Leader节点,并继续处理消息。因此,即使某个Broker节点出现故障,也不会导致数据丢失。
消息落盘机制
Kafka使用消息落盘机制来保证消息的可靠性。在Kafka中,消息首先会被写入到PageCache中,然后再异步地写入到磁盘中。因此,即使发生宕机等意外情况,已经写入PageCache中的消息也不会丢失。
在Kafka中,可以通过以下方式来保证消息的落盘:
- 设置acks为all:在生产者端,可以将acks设置为all来保证消息的可靠性。这样可以保证只有当消息被写入到所有Partition的副本中,并且写入到磁盘后才会认为发送成功。
- 设置min.insync.replicas:在生产者端,可以设置min.insync.replicas来保证消息的可靠性。这个参数指定了至少有多少个Partition的副本需要确认写入磁盘后才认为发送成功。默认值为1,可以根据实际需求进行配置。
实际案例
下面给出一个实际案例来说明如何保证Kafka不丢失消息。假设有一个消息生产者需要将消息发送到Kafka中,并且要求消息的可靠性。在生产者端,可以进行如下配置:
以上是生产者端的配置。其中,acks参数被设置为all,表示只有当消息被写入到所有Partition的副本中,并且写入到磁盘后才会认为发送成功。min.insync.replicas参数被设置为2,表示至少有2个Partition的副本需要确认写入磁盘后才认为发送成功。
在消费者端,可以进行如下配置:
bootstrap.servers=broker1:9092,broker2:9092,broker3:9092
group.id=my-group
auto.offset.reset=latest
enable.auto.commit=false其中,group.id参数指定了消费者组的名称,auto.offset.reset参数被设置为latest,表示当消费者第一次启动时,从最新的消息开始消费。enable.auto.commit参数被设置为false,表示使用手动提交offset的方式来保证消息的可靠性。在消费消息时,可以使用以下代码来实现手动提交offset的方式:
while (true) {
ConsumerRecordsString, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecordString, String> record : records) {
processRecord(record);
}
consumer.commitAsync();
}其中,poll方法从Kafka中拉取消息,processRecord方法处理消息,commitAsync方法异步提交offset。
在以上配置和代码的基础上,就可以保证Kafka不丢失消息了。如果在生产者或消费者端出现故障,可以根据以上介绍的方法来保证消息的可靠性。除此之外,还可以结合Kafka的监控工具和告警机制来实时监控Kafka的运行状态,及时发现并解决问题。
补充:一文读懂kafka的重试机制和如何保证有序性?
总结
Kafka作为一款高吞吐、低延迟的分布式消息队列,在各行各业得到了广泛的应用。在使用Kafka时,需要注意消息的可靠性问题,以保证数据不会丢失。为了保证消息的可靠性,可以采用多种方法,包括配置参数、消费者端的手动提交offset、副本机制和消息落盘机制等。在实际使用中,还需要结合监控工具和告警机制来及时发现并解决问题。
我是终端研发部的小于哥
@终端研发部
每天专注技术开发小技巧,技术教程进阶,职场经验,面试的分享,希望我的回答能够帮助到你哈,笔芯~
文章来源于互联网:面试题:说说你如何保证Kafka不丢失消息?

