
关于pprof的文章在网上已是汗牛充栋,却是千篇一律的命令介绍,鲜有真正实操的,本文将参考Go社区资料,结合自己的经验,实战Go程序的性能分析与优化过程。
优化思路
首先说一下性能优化的一般思路。系统性能的分析优化,一定是从大到小的步骤来进行的,即从业务架构的优化,到系统架构的优化,再到系统模块间的优化,最后到代码编写层面的优化。业务架构的优化是最具性价比的,技术难度相对较小,却可以带来大幅的性能提升。比如通过和同事或外部门沟通,减少了一些接口调用或者去掉了不必要的复杂的业务逻辑,可以轻松提升整个系统的性能。
系统架构的优化,比如加入缓存,由http改进为rpc等,也可以在少量投入下带来较大的性能提升。最后是程序代码级别的性能优化,这又分为两方面,一是合格的数据结构与使用,二才是在此基础上的性能剖析。比如在Go语言中使用slice这种方便的数据结构时,尽可能提前申请足够的内存防止append超过容量时的内存申请和数据拷贝;使用并发保护时尽量由RWMutex 代替mutex,甚至在极高并发场景下使用更细粒度的原子操作代替锁等等。
优化实践
下面进入正文,待优化程序是社区中一个例子,代码有点长,实现的算法是著名的计算机科学家Tarjan的求图的强连通分量算法,关于这个算法的思想请自行google(就别自行百度了~)。以下为实操过程(会有那么一丢丢长。。。):
初始版本代码 havlak1.go:
// Go from multi-language-benchmark/src/havlak/go_pro// Copyright 2011 Google Inc.//// Licensed under the Apache License, Version 2.0 (the "License");// you may not use this file except in compliance with the License.// You may obtain a copy of the License at//// http://www.apache.org/licenses/LICENSE-2.0//// Unless required by applicable law or agreed to in writing, software// distributed under the License is distributed on an "AS IS" BASIS,// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.// See the License for the specific language governing permissions and// limitations under the License.// Test Program for the Havlak loop finder.//// This program constructs a fairly large control flow// graph and performs loop recognition. This is the Go// version.//package mainimport ( "flag" "fmt" "log" "os" "runtime/pprof")type BasicBlock struct { Name int InEdges []*BasicBlock OutEdges []*BasicBlock}func NewBasicBlock(name int) *BasicBlock { return &BasicBlock{Name: name}}func (bb *BasicBlock) Dump() { fmt.Printf("BB#%06d:", bb.Name) if len(bb.InEdges) > 0 { fmt.Printf(" in :") for _, iter := range bb.InEdges { fmt.Printf(" BB#%06d", iter.Name) } } if len(bb.OutEdges) > 0 { fmt.Print(" out:") for _, iter := range bb.OutEdges { fmt.Printf(" BB#%06d", iter.Name) } } fmt.Printf("n")}func (bb *BasicBlock) NumPred() int { return len(bb.InEdges)}func (bb *BasicBlock) NumSucc() int { return len(bb.OutEdges)}func (bb *BasicBlock) AddInEdge(from *BasicBlock) { bb.InEdges = append(bb.InEdges, from)}func (bb *BasicBlock) AddOutEdge(to *BasicBlock) { bb.OutEdges = append(bb.OutEdges, to)}//-----------------------------------------------------------type CFG struct { Blocks []*BasicBlock Start *BasicBlock}func NewCFG() *CFG { return &CFG{}}func (cfg *CFG) NumNodes() int { return len(cfg.Blocks)}func (cfg *CFG) CreateNode(node int) *BasicBlock { if node 0 { for _, nodeV := range nodeW.InEdges { v := number[nodeV] if v == unvisited { continue // dead node } if isAncestor(w, v, last) { backPreds[w] = append(backPreds[w], v) } else { nonBackPreds[w][v] = true } } } } // Start node is root of all other loops. header[0] = 0 // Step c: // // The outer loop, unchanged from Tarjan. It does nothing except // for those nodes which are the destinations of backedges. // For a header node w, we chase backward from the sources of the // backedges adding nodes to the set P, representing the body of // the loop headed by w. // // By running through the nodes in reverse of the DFST preorder, // we ensure that inner loop headers will be processed before the // headers for surrounding loops. // for w := size - 1; w >= 0; w-- { // this is 'P' in Havlak's paper var nodePool []*UnionFindNode nodeW := nodes[w].bb if nodeW == nil { continue // dead BB } // Step d: for _, v := range backPreds[w] { if v != w { nodePool = append(nodePool, nodes[v].FindSet()) } else { types[w] = bbSelf } } // Copy nodePool to workList. // workList := append([]*UnionFindNode(nil), nodePool...) if len(nodePool) != 0 { types[w] = bbReducible } // work the list... // for len(workList) > 0 { x := workList[0] workList = workList[1:] // Step e: // // Step e represents the main difference from Tarjan's method. // Chasing upwards from the sources of a node w's backedges. If // there is a node y' that is not a descendant of w, w is marked // the header of an irreducible loop, there is another entry // into this loop that avoids w. // // The algorithm has degenerated. Break and // return in this case. // nonBackSize := len(nonBackPreds[x.dfsNumber]) if nonBackSize > maxNonBackPreds { return } for iter := range nonBackPreds[x.dfsNumber] { y := nodes[iter] ydash := y.FindSet() if !isAncestor(w, ydash.dfsNumber, last) { types[w] = bbIrreducible nonBackPreds[w][ydash.dfsNumber] = true } else { if ydash.dfsNumber != w { if !listContainsNode(nodePool, ydash) { workList = append(workList, ydash) nodePool = append(nodePool, ydash) } } } } } // Collapse/Unionize nodes in a SCC to a single node // For every SCC found, create a loop descriptor and link it in. // if (len(nodePool) > 0) || (types[w] == bbSelf) { loop := lsgraph.NewLoop() loop.SetHeader(nodeW) if types[w] != bbIrreducible { loop.IsReducible = true } // At this point, one can set attributes to the loop, such as: // // the bottom node: // iter = backPreds[w].begin(); // loop bottom is: nodes[iter].node); // // the number of backedges: // backPreds[w].size() // // whether this loop is reducible: // type[w] != BasicBlockClass.bbIrreducible // nodes[w].loop = loop for _, node := range nodePool { // Add nodes to loop descriptor. header[node.dfsNumber] = w node.Union(nodes[w]) // Nested loops are not added, but linked together. if node.loop != nil { node.loop.Parent = loop } else { loop.AddNode(node.bb) } } lsgraph.AddLoop(loop) } // nodePool.size } // Step c}// External entry point.func FindHavlakLoops(cfgraph *CFG, lsgraph *LSG) int { FindLoops(cfgraph, lsgraph) return lsgraph.NumLoops()}//======================================================// Scaffold Code//======================================================// Basic representation of loops, a loop has an entry point,// one or more exit edges, a set of basic blocks, and potentially// an outer loop - a "parent" loop.//// Furthermore, it can have any set of properties, e.g.,// it can be an irreducible loop, have control flow, be// a candidate for transformations, and what not.//type SimpleLoop struct { // No set, use map to bool basicBlocks map[*BasicBlock]bool Children map[*SimpleLoop]bool Parent *SimpleLoop header *BasicBlock IsRoot bool IsReducible bool Counter int NestingLevel int DepthLevel int}func (loop *SimpleLoop) AddNode(bb *BasicBlock) { loop.basicBlocks[bb] = true}func (loop *SimpleLoop) AddChildLoop(child *SimpleLoop) { loop.Children[child] = true}func (loop *SimpleLoop) Dump(indent int) { for i := 0; i 0 if len(loop.Children) > 0 { fmt.Printf("Children: ") for ll := range loop.Children { fmt.Printf("loop-%d", ll.Counter) } } if len(loop.basicBlocks) > 0 { fmt.Printf("(") for bb := range loop.basicBlocks { fmt.Printf("BB#%06d ", bb.Name) if loop.header == bb { fmt.Printf("*") } } fmt.Printf("b)") } fmt.Printf("n")}func (loop *SimpleLoop) SetParent(parent *SimpleLoop) { loop.Parent = parent loop.Parent.AddChildLoop(loop)}func (loop *SimpleLoop) SetHeader(bb *BasicBlock) { loop.AddNode(bb) loop.header = bb}//------------------------------------// Helper (No templates or such)//func max(x, y int) int { if x > y { return x } return y}// LoopStructureGraph//// Maintain loop structure for a given CFG.//// Two values are maintained for this loop graph, depth, and nesting level.// For example://// loop nesting level depth//----------------------------------------// loop-0 2 0// loop-1 1 1// loop-3 1 1// loop-2 0 2//var loopCounter = 0type LSG struct { root *SimpleLoop loops []*SimpleLoop}func NewLSG() *LSG { lsg := new(LSG) lsg.root = lsg.NewLoop() lsg.root.NestingLevel = 0 return lsg}func (lsg *LSG) NewLoop() *SimpleLoop { loop := new(SimpleLoop) loop.basicBlocks = make(map[*BasicBlock]bool) loop.Children = make(map[*SimpleLoop]bool) loop.Parent = nil loop.header = nil loop.Counter = loopCounter loopCounter++ return loop}func (lsg *LSG) AddLoop(loop *SimpleLoop) { lsg.loops = append(lsg.loops, loop)}func (lsg *LSG) Dump() { lsg.dump(lsg.root, 0)}func (lsg *LSG) dump(loop *SimpleLoop, indent int) { loop.Dump(indent) for ll := range loop.Children { lsg.dump(ll, indent+1) }}func (lsg *LSG) CalculateNestingLevel() { for _, sl := range lsg.loops { if sl.IsRoot { continue } if sl.Parent == nil { sl.SetParent(lsg.root) } } lsg.calculateNestingLevel(lsg.root, 0)}func (lsg *LSG) calculateNestingLevel(loop *SimpleLoop, depth int) { loop.DepthLevel = depth for ll := range loop.Children { lsg.calculateNestingLevel(ll, depth+1) ll.NestingLevel = max(loop.NestingLevel, ll.NestingLevel+1) }}func (lsg *LSG) NumLoops() int { return len(lsg.loops)}func (lsg *LSG) Root() *SimpleLoop { return lsg.root}//======================================================// Testing Code//======================================================func buildDiamond(cfgraph *CFG, start int) int { bb0 := start NewBasicBlockEdge(cfgraph, bb0, bb0+1) NewBasicBlockEdge(cfgraph, bb0, bb0+2) NewBasicBlockEdge(cfgraph, bb0+1, bb0+3) NewBasicBlockEdge(cfgraph, bb0+2, bb0+3) return bb0 + 3}func buildConnect(cfgraph *CFG, start int, end int) { NewBasicBlockEdge(cfgraph, start, end)}func buildStraight(cfgraph *CFG, start int, n int) int { for i := 0; i 我们借助macbook系统上的time命令来打印程序运行的时间(内核态、用户态、总时间):
编译后运行程序:


用户态耗时23.07s,内核态耗时0.4s,总耗时13.7s(用了两个核,170%)。因为程序里面已经先开启了pprof统计cpu耗时,直接top命令看:

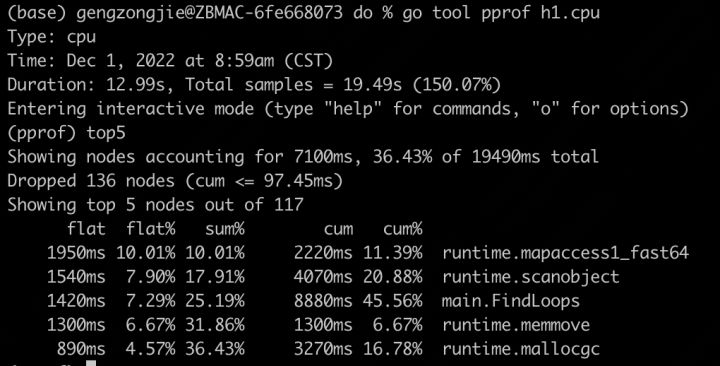
可以看到,pprof数据采集持续了12.99s,采样时长是19.49s(还是两核的缘故)。
这里要说一下,无论是cpu耗时统计还是内存占用统计,都是间隔采样。cpu耗时时每隔一段时间(大概是10ms)对调用栈的函数进行记录,最后分析在所有的记录次数中,各个函数出现的次数,包括在运行中的次数,和入栈次数(说明它调用了别的函数)。内存占用统计是每分配512K记录一次分配路径。
耗时最多的是mapaccess1_fast64,这是运行时中的map读写时的数据查询函数。如果编译程序时没有禁用内联,看到的会有所不同,其中会显示FindHavlakLoops函数,并标识为inline。因为FindHavlakLoops里面就调用了FindLoops,所以在编译器会直接把这个函数展开,用FindLoops替换FindHavlakLoops函数。也可以在不禁用内联编译时,设置pprof的noinlines开关为true,默认为false,即noinlines=true。
这里看到最大的函数并不是业务函数而是系统函数,那没啥好优化系统函数的(只能是咱用的不对了呗~)。就看是哪里调用的这个系统函数:
web mapaccess1_fast64


可以看到,调用最多的是DFS和FindLoops。那就看看这俩函数里面是怎么使用map的,来看DFS:

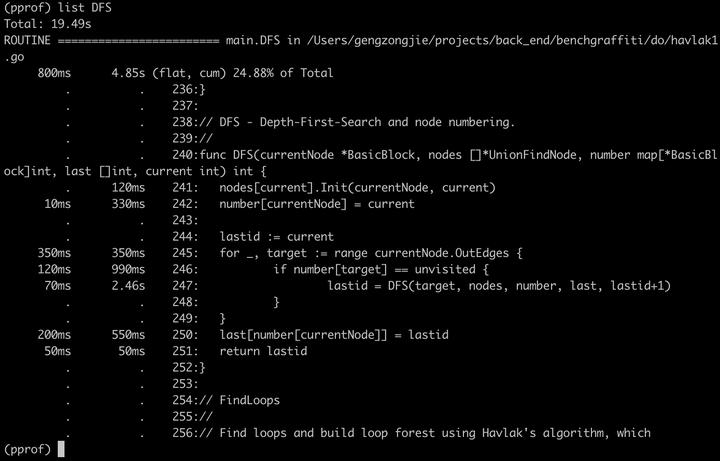
可以看到,DFS函数里耗时较长又是map操作的,是242 246 和250三行。对于这里的优化方法,是用list结构代替map结构,因为能用list达到效果的情况下没必要用map。这个咋一看没问题,但好像又有点别扭对吧?其实是因为这个程序的本身特点,这里有明显的一点,就是BasicBlock结构的特殊性,本身的Name属性就是自身的索引下标。查找某个BasicBlock不需要使用map来记录,直接通过下标访问显然是最低的时间复杂度(关于map和list的时间复杂度就不多说了,map看起来是O1,但其实没有考虑hash计算本身的过程和解决hash冲突的成本,而list是必然的O1)。通过把这部分的map修改为list数据结构,版本H2,再编译查看耗时情况:


此时耗时降低到了8s。再次查看cpu耗时分布:

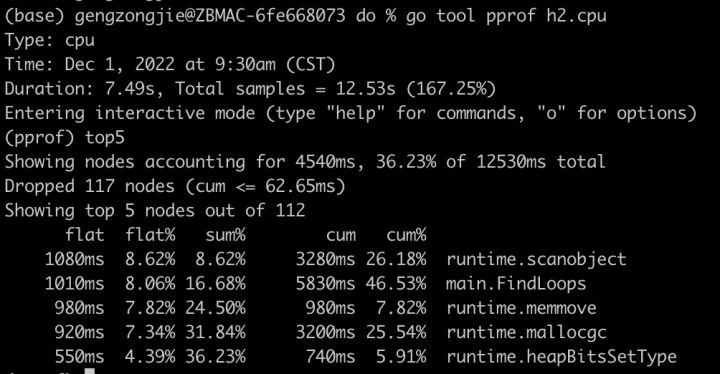
可以看到,top1变成了scanobject函数,不再是map读写了。看到这个函数,以及下边的mallocgc,我们要知道,这都是内存相关的,前者是内存对象扫描的处理函数,是垃圾回收三色标记的一个过程,后者则是直接管理内存分配和回收的(注意是同时负责内存分配和回收,malloc && gc)。这说明目前程序花了很多时间在进行内存管理,看比例是8%。那就要分析一下了,是什么东西产生了这么多内存变化,合不合理。分析内存,就是pprof的memprofile功能了。添加一下相关的内存统计代码,具体怎么添加大家肯定都会,就不贴了(网上多得是)。添加完之后,重新编译生成版本H3,执行H3,生成对应的内存监测文件:


查看内存的分配情况,在这里不禁止内联,因为在实际运行时该内联的函数也是会被展开替换掉的:

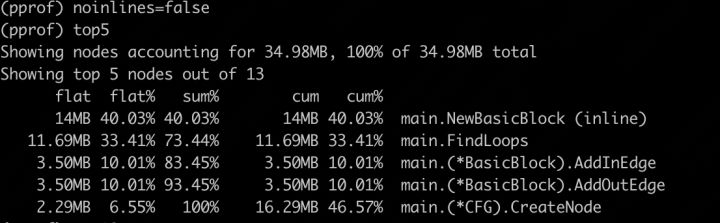
可以看到,节点创建是第一,FindLoops是第二。因为创建BasicBlock首先很简单,没有复杂的过程,其次这是程序中的一个基础对象结构,若要改结构体,那可能涉及到算法也得改,这个显然是不合适的,不仅可能改出bug,还可能收益不高。那我们就顺着看第二位的FindLoops,这个就是前边我们看到的调用mapaccess内置函数的另一个业务函数,所以优化的方法跟上面类似,还是优化map的使用,替换为list。这里有一点特殊的是,替换成list之后,map的追加需要改一下,加一个判断重复的逻辑,所以新加了一个appendUnique方法。再次编译,版本H4,查看耗时:


这时程序耗时降到了5.6s。再次查看内存分配,确认优化效果:

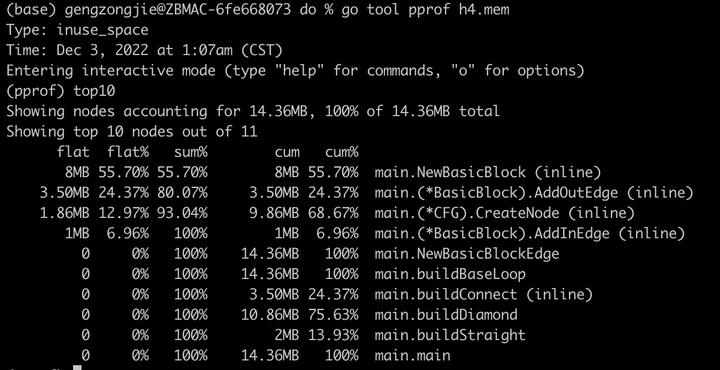
可以看到,FindLoops函数已经不在高位,内存消耗降下去了。再看一下此时的cpu耗时分布:

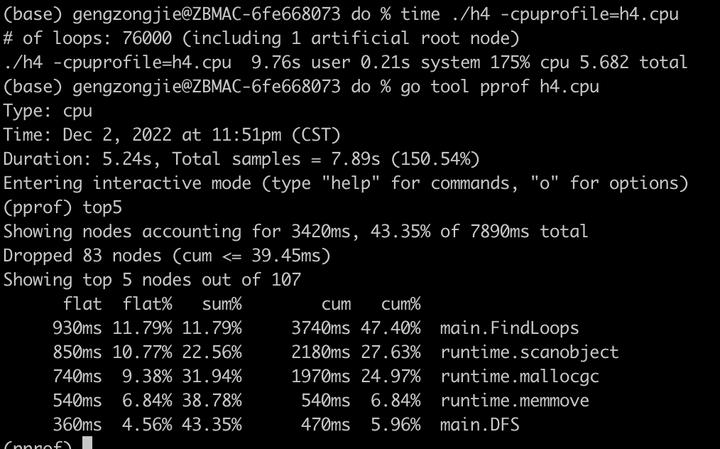
可以看到,FindLoops成为top1,scanobject函数成了第二位。这就对了,因为我们就是要让cpu更多的去运行业务代码,把时间花到真正需要的地方。
这时就可以进行下一轮的性能优化了(这就是性能调优,一遍一遍的排查耗时,压缩不必要的cpu时间,压榨计算性能)。继续看一下此时FindLoops到底在哪儿化的时间多,是否合理:

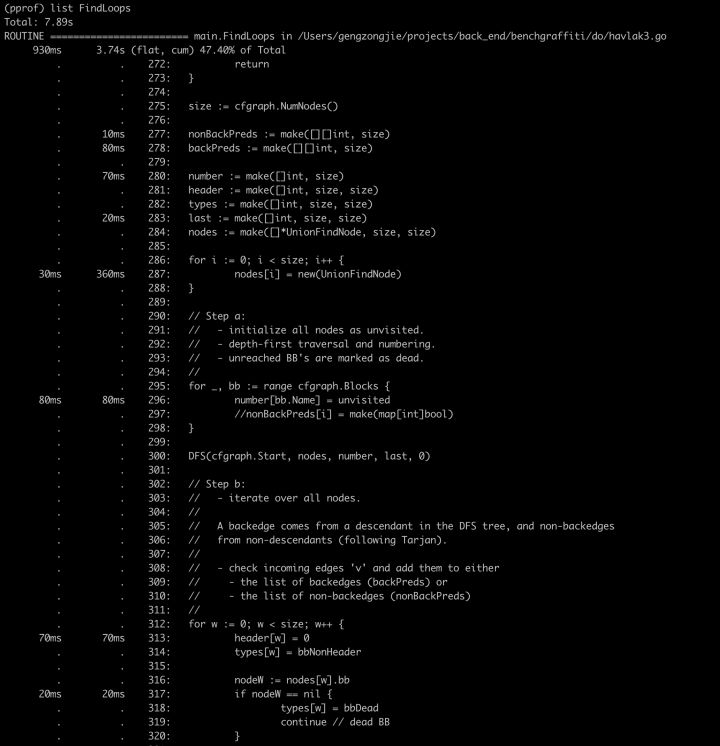
从各个语句的耗时来看,好像没啥大问题,没有很离谱的耗时(360ms那行是因为循环的缘故)。这说明编码上没有大问题,按照我们前边一开始说的程序优化的步骤,就需要往上找了,看能不能优化逻辑来减少不必要的计算,以达到提升性能的目的(即,每一个计算步骤处理的都没啥大问题了,那能不能少算点儿)。这里FindLoops在程序入口,花了不少时间来初始化一系列临时变量,加起来有180ms,这就意味着每次调用FindLoops函数,都要先花180ms的准备工作。这部分临时变量的多次创建+初始化,可以通过加内存缓存的方式来减少重复创建和申请,这里涉及到的标准解法其实就是对象池(像Go创建的web服务,在并发量很高的情况下,每一次http请求的解析都需要创建对象+申请内存+反序列这一系列的初始动作,这时就可以借助sync.Pool来减少这种重复工作,提升性能)。同理,这里也是加入了一个内存缓存对象cache:

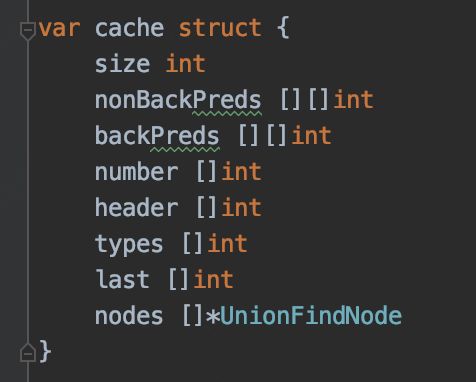
把原本的内存申请初始化过程做了替换。在原有缓存不够的情况下,申请新的变量,否者截取原有缓存使用,减少内存申请:

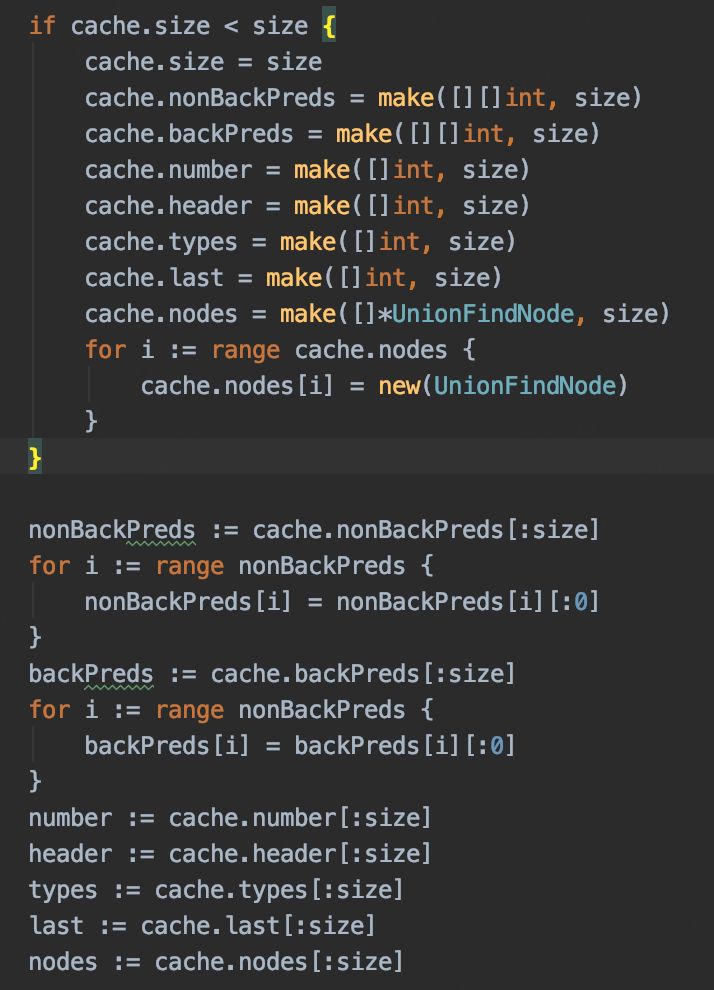
调整完毕后,编译新版本H5,再看下耗时:


这时候程序的耗时已经降到4.1s,相比一开始的13.7s,已经提升了两倍多。看下现在的cpu耗时分布:

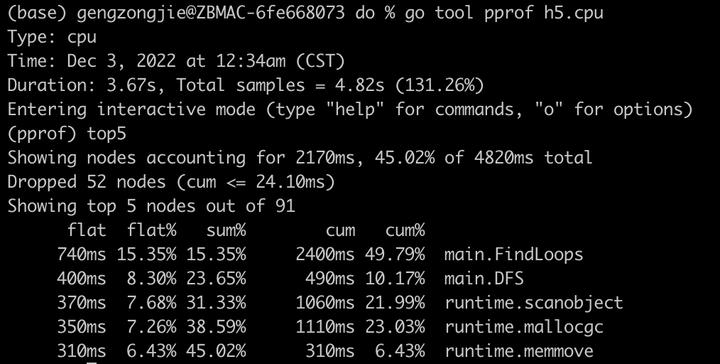
可以看到,相比上次的分布,前两位都是业务代码函数了,说明进一步提高了业务代码的耗时占比,降低了无关系统函数的负载。这种直接使用全局变量的方式加cache不是并发安全的,但是因为这里程序的逻辑本身也不是并发的,所以这里没问题。
到这里,实操的优化过程就走完了。提炼总结一下优化的步骤和使用的主要方法命令有:
1.通过top5查看cpu耗时:确定是字典数据操作占比最大;
2.通过web命令查看是谁主要调用了字典操作函数:确定有DFS和FindLoops;
3.使用list 命令查看DFS函数中每行代码的耗时,找到跟map操作相关的部分,确定优化方法:把map换成list;
4.重新运行,再用top命令查看cpu耗时分布:找到耗时最大的是内存对象扫描函数scanobject;
5.加入内存剖析代码,运行查看内存分配的大小分布:确定FindLoops占用较大;
6.使用list命令查看FindLoops函数的每行内存开销:确定是map创建占用内存较大;
7.同样使用list数据结构替换map,重新运行,再看内存大小分布:确定FindLoops已不在高位,同时再看CPU耗时时,scanobject已经降下去了,目的达到;
8.此时又开始新的一轮排查,继续查看cpu耗时排行榜,FindLoops耗时居首;
9.继续使用list方法看FindLoops函数每行的耗时,没有明显的问题。那就要换思路,从排查编码问题转换为排查逻辑问题,减少计算过程:这里是加缓存;
10.加完缓存看到性能明显提升了,说明优化对了。这时又该循环进入下一轮的排查的优化了,以此往复。。。直到压榨出我们能达到的最大性能!
以上就是本次程序优化的整体步骤和思路,过程中秉持的思路方法是一贯的,就是不断的用pprof排查top级的函数耗时和内存占用,通过优化数据结构、减少不必要的计算过程、降低内存分配和回收的负担等方式来提升性能,这一点对所有的程序都适用,也是后续可以借鉴的方法论。
两点感悟:
1.优化程序的大前提是你一定要对程序有足够深入的理解!(或者说我们不能优化程序优化出bug来啊。。。)。最后生产H6版本,之所以又对性能提升了一倍,全是建立在作者对程序完全理解的基础之上的,所以他才可以调整循环逻辑,复用程序对象,调整调用逻辑等等。这一层再往上层思考,就到了程序逻辑,系统架构内置整体的业务架构层面了。这其实就又回到了一开始我们说的程序优化由大到小的总体思路上了。
2.带GC的语言相比不带的,反而更考验内存管理的技术。Go语言在开发效率上的提升,是把垃圾回收交给了系统来处理,但别忘了,消耗的依然是我们自己的cpu时间(羊毛,那不得从羊身上来...)。所以我们在使用每种结构体,进行每种计算操作时,都要明白其背后涉及的内存开销,要把内存变化放到潜意识里去管理。
以上就是本次pprof优化Go程序的实操过程及总结感想,供参考,感谢~
欢迎来京东云开发者社区交流技术,原文作者:耿宗杰

