
作者:koka
1. Slice 扩容
本文中的示例和代码都是基于 Go 当前的最新版本(Go1.20.2),Go 还一直在演化之前和之后的版本可能会有些许的差异。
当 Slice 的 Capacity 不足时,需要进行容量扩容,他的 Capacity 是如何增长的?
请看下面一段简单的代码:
func main() {
arr := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18}
s2 := []int{}
for i := 0; i 
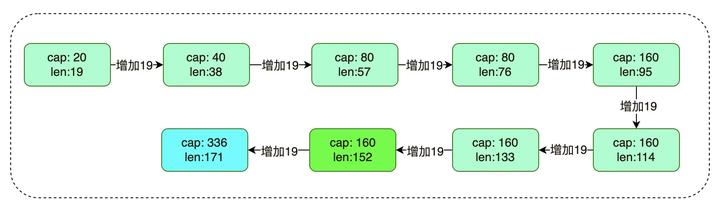
从上面可以看出,round 7 到 round 8,slice 的 cap,直接从 160->336,what ?为啥不是 320,320 也是 8 字节对齐的呀。我们跳转到 append 函数的声明如下:
/*
Package builtin provides documentation for Go's predeclared identifiers.
The items documented here are not actually in package builtin
but their descriptions here allow godoc to present documentation
for the language's special identifiers.
*/
package builtin
// The append built-in function appends elements to the end of a slice. If
// it has sufficient capacity, the destination is resliced to accommodate the
// new elements. If it does not, a new underlying array will be allocated.
// Append returns the updated slice. It is therefore necessary to store the
// result of append, often in the variable holding the slice itself:
//
// slice = append(slice, elem1, elem2)
// slice = append(slice, anotherSlice...)
//
// As a special case, it is legal to append a string to a byte slice, like this:
//
// slice = append([]byte("hello "), "world"...)
func append(slice []Type, elems ...Type) []Type
但是并没有找到 append 的定义,到这里我们提出两个问题:
- [ cap : 160, len : 152 ]的 slice,添加 19 个元素,cap 变为 336,而不是 320?
- 函数 append 的定义在哪?
1.1 扩容算法
我们看到只有声明没有定义,从上面的注释可以看出,这里的预声明是给 godoc 生成文档用的实际的定义并不在这里。怎样找到 builtin 函数的定义呢?我们可以使用命令 go build -gcflags -S main.go 查看汇编代码可以看到,append 已经被 runtime.growslice 替换。
………………
0x0234 00564 MOVQ DX, main..autotmp_36+80(SP)
0x0239 00569 LEAQ type.int(SB), AX
0x0240 00576 MOVQ CX, DI
0x0243 00579 MOVQ DX, CX
0x0246 00582 PCDATA $1, $0
0x0246 00582 CALL runtime.growslice(SB)
0x024b 00587 MOVQ main..autotmp_36+80(SP), DX
0x0250 00592 MOVQ AX, BX
0x0253 00595 JMP 303
0x0258 00600 PCDATA $1, $-1
0x0258 00600 MOVQ 296(SP), BP
0x0260 00608 ADDQ $304, SP
………………
很明显这是在编译的过程中,被替换的,后面会详细说下这个过程。现在我们可以找到函数定义:runtime.growslice 这代码很好理解,如果需要申请的 cap 是原来的 2 倍,则 newcap 就是需要申请的 cap。如果需要申请的 cap 不到原来的 2 倍,小于阈值 256 直接按照 2 倍处理,大于阈值的话按照 1.25 倍+0.75*阈值的平滑因子进行增长。

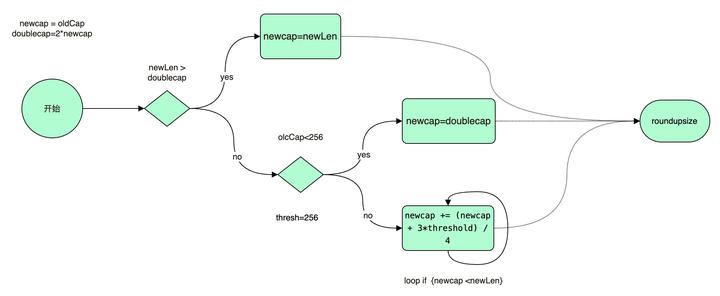
1.2 内存对齐
经过这样计算得到的 newcap 还不是最终的值,最终的值还需要经过内存对齐,这样对齐的原因跟 Go 的内存分配有关,对齐后内存分配会更有效率。下面这个 roundupsize 函数,返回的就是对齐后需要的的内存大小。
func roundupsize(size uintptr) uintptr {
if size 1.3 对齐原理
本篇只是浅谈一下 Go 的内存管理,解释清楚 roundupsize 函数,为什么这样去返回。runtime.mspan 是 Go 内存管理的基本单元,mspan 有个字段 spanClass,是跨度类,是对 mspan 大小级别的划分,它决定了内存管理单元中存储的对象大小和个数。
Size Class: Go 对于 32KB 以内的小对象,会将这些小对象按不同大小划分为多个内存刻度 Size Class,是不同大小对象 Object Size 按顺序排序的序号,如 0,1,2,3。每个 Size Class 都对应一个对象大小即 Object Size 如:0B ,8B,16B,32B 等。
Go 内存管理模块中一共包含 68(包括 0 在内)种内存刻度 Size Class,每一个 Size Class 都会存储特定大小即 Object Size 的对象,并且包含特定数量的页数 npages,Size Class 和 Object Size 及页数 npages 的关系,存储在 runtime.class_to_size 和 runtime.class_to_allocnpages 等变量中:
// [class] : Size Class 规格
// [bytes/obj] : Object Size 对外提供的object的大小
// [bytes/span]: 当前object对应的span的大小
// [objects] : 当前span一共能存放多少objects
// [tail waste]: 当前span平均分为N个object,会有多少的内存浪费
// [max waste] : 当前Size Class 最大可能浪费空间的百分比
// [min align] : 最小对齐大小,最大值为页的大小8192,其他为class size的0的个数,2的次方
// class bytes/obj bytes/span objects tail waste max waste min align
// 1 8 8192 1024 0 87.50% 8
// 2 16 8192 512 0 43.75% 16
// 3 24 8192 341 8 29.24% 8
// 4 32 8192 256 0 21.88% 32
// 5 48 8192 170 32 31.52% 16
// 6 64 8192 128 0 23.44% 64
// 7 80 8192 102 32 19.07% 16
// 8 96 8192 85 32 15.95% 32
…………
// 66 28672 57344 2 0 4.91% 4096
// 67 32768 32768 1 0 12.50% 8192
const (
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 68
_PageShift = 13
)
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 24, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
var size_to_class8 = [smallSizeMax/smallSizeDiv + 1]uint8{0, 1, 2, 3, 4, 5, 5, 6, 6, 7, 7, 8, 8, 9, 9, 10, 10, 11, 11, 12, 12, 13, 13, 14, 14, 15, 15, 16, 16, 17, 17, 18, 18, 19, 19, 19, 19, 20, 20, 20, 20, 21, 21, 21, 21, 22, 22, 22, 22, 23, 23, 23, 23, 24, 24, 24, 24, 25, 25, 25, 25, 26, 26, 26, 26, 27, 27, 27, 27, 27, 27, 27, 27, 28, 28, 28, 28, 28, 28, 28, 28, 29, 29, 29, 29, 29, 29, 29, 29, 30, 30, 30, 30, 30, 30, 30, 30, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 31, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32}
var size_to_class128 = [(_MaxSmallSize-smallSizeMax)/largeSizeDiv + 1]uint8{32, 33, 34, 35, 36, 37, 37, 38, 38, 39, 39, 40, 40, 40, 41, 41, 41, 42, 43, 43, 44, 44, 44, 44, 44, 45, 45, 45, 45, 45, 45, 46, 46, 46, 46, 47, 47, 47, 47, 47, 47, 48, 48, 48, 49, 49, 50, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 52, 52, 52, 52, 52, 52, 52, 52, 52, 52, 53, 53, 54, 54, 54, 54, 55, 55, 55, 55, 55, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 56, 57, 57, 57, 57, 57, 57, 57, 57, 57, 57, 58, 58, 58, 58, 58, 58, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 59, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 60, 61, 61, 61, 61, 61, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 62, 63, 63, 63, 63, 63, 63, 63, 63, 63, 63, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 64, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 65, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 66, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67, 67}
** size_to_class8**
size_to_class8 数组,第 i 个元素表示( (i - 1) _ 8,i _ 8] ,smallSizeDiv=8 对应的 sizeclass,举个例子 i=2 时,size_to_class8 [2] = 2,对应的 size_class[2] = 16。也就是这个区间(8, 16 ]的分配的大小都为 16(bit)。size_to_class8 是用于
size_to_class128
与 size_to_class8 类似,size_to_calss128 用于 (smallSizeMax-8, _MaxSmallSize) 区间内存分配 class 查找。
tail waste/max waste
tail waste 以上面的 class 8 为例,对象大小的为 96 字节,一页大小为 8192 最多可以存 85 个对象,8192-96*85=32,存在 32 个字节的尾部浪费。
max waste 当存储的对象都是 81 字节时,( (96-81)*85 + 32 ) / 8192 = 0.1595,即存在 15.95%的最大内存浪费。
1.4 小结
回到上面 slice 的 [cap:160, len:152] ->[cap:336, len:171] ,增加 19 个字节后 cap 从 160 增长到 336, 看下面的算法
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap maxAlloc/goarch.PtrSize
newcap = int(capmem / goarch.PtrSize)
…………
newcap=320 经过 roundupsize(320 * 8) = 2560,
class_to_size[size_to_class128[ceil(2560 - 1024)/128] =
class_to_size[size_to_class128[12]= class_to_size[40] = 2688
经过上面查找到 class_to_size[40]的 object 大小为 2688bits,2688bits/8=336 字节,从而得到 newcap 的大小为 336 字节。
2、Go 语言编译
下面来解答下第一个问题,Go 语言在编译的时候,如何把 builtin 函数 append,转换成 runtime.growslice 的,这涉及到编译原理,下面我们来逐步分析下 Go 语言的编译过程。
2.1 基础知识
经典的编译原理一般包括如下几个过程:词法分析、语法分析、语意分析、中间代码生成、代码优化、机器代码生成。


通常将词语分析、语法分析、语意分析、中间代码生成称之为"front-end",而将目标代码的生成和优化称之为"back-end",近来也有人将 back-end 其中的一大部分工作抽离出来称之为"middle-end"。
2.2 词法分析&语法分析(Parsing)
在编译的第一阶段,源代码被标记化(词法分析)、解析(语法分析),并为每个源文件构建一个语法树(AST)。每个语法树都是相应源文件的精确表示,节点对应于源的各种元素,例如表达式、声明和语句。 语法树还包括用于错误报告和调试信息创建的位置信息。以下面一段简单的代码 append.go 为例:
1 package main
2
3 func main() {
4 s2 := []int{}
5 s2 = append(s2, 100)
6}
上述代码的 tokenized 我们可以打印出来如下:
1:1 package "package"
1:9 IDENT "main"
1:13 ; "n"
3:1 func "func"
3:6 IDENT "main"
3:10 ( ""
3:11 ) ""
3:13 { ""
4:2 IDENT "s2"
4:5 := ""
4:8 [ ""
4:9 ] ""
4:10 IDENT "int"
4:13 { ""
4:14 } ""
4:15 ; "n"
5:2 IDENT "s2"
5:5 = ""
5:7 IDENT "append"
5:13 ( ""
5:14 IDENT "s2"
5:16 , ""
5:18 INT "100"
5:21 ) ""
5:22 ; "n"
6:1 } ""
6:2 ; "n"
一旦经过 tokenized,通过语法分析去构造语法树。通过 go 提供的库函数 token.NewFileSet 等可以打印出 append.go 的抽象语法树:
0 *ast.File {
1 . Package: append.go:1:1
2 . Name: *ast.Ident {
3 . . NamePos: append.go:1:9
4 . . Name: "main"
5 . }
6 . Decls: []ast.Decl (len = 1) {
7 . . 0: *ast.FuncDecl {
8 . . . Name: *ast.Ident {
9 . . . . NamePos: append.go:3:6
10 . . . . Name: "main"
11 . . . . Obj: *ast.Object {
12 . . . . . Kind: func
13 . . . . . Name: "main"
14 . . . . . Decl: *(obj @ 7)
15 . . . . }
16 . . . }
17 . . . Type: *ast.FuncType {
18 . . . . Func: append.go:3:1
19 . . . . Params: *ast.FieldList {
20 . . . . . Opening: append.go:3:10
21 . . . . . Closing: append.go:3:11
22 . . . . }
23 . . . }
24 . . . Body: *ast.BlockStmt {
25 . . . . Lbrace: append.go:3:13
26 . . . . List: []ast.Stmt (len = 2) {
27 . . . . . 0: *ast.AssignStmt {
28 . . . . . . Lhs: []ast.Expr (len = 1) {
29 . . . . . . . 0: *ast.Ident {
30 . . . . . . . . NamePos: append.go:4:2
31 . . . . . . . . Name: "s2"
32 . . . . . . . . Obj: *ast.Object {
33 . . . . . . . . . Kind: var
34 . . . . . . . . . Name: "s2"
35 . . . . . . . . . Decl: *(obj @ 27)
36 . . . . . . . . }
37 . . . . . . . }
38 . . . . . . }
39 . . . . . . TokPos: append.go:4:5
40 . . . . . . Tok: :=
41 . . . . . . Rhs: []ast.Expr (len = 1) {
42 . . . . . . . 0: *ast.CompositeLit {
43 . . . . . . . . Type: *ast.ArrayType {
44 . . . . . . . . . Lbrack: append.go:4:8
45 . . . . . . . . . Elt: *ast.Ident {
46 . . . . . . . . . . NamePos: append.go:4:10
47 . . . . . . . . . . Name: "int"
48 . . . . . . . . . }
49 . . . . . . . . }
50 . . . . . . . . Lbrace: append.go:4:13
51 . . . . . . . . Rbrace: append.go:4:14
52 . . . . . . . . Incomplete: false
53 . . . . . . . }
54 . . . . . . }
55 . . . . . }
56 . . . . . 1: *ast.AssignStmt {
57 . . . . . . Lhs: []ast.Expr (len = 1) {
58 . . . . . . . 0: *ast.Ident {
59 . . . . . . . . NamePos: append.go:5:2
60 . . . . . . . . Name: "s2"
61 . . . . . . . . Obj: *(obj @ 32)
62 . . . . . . . }
63 . . . . . . }
64 . . . . . . TokPos: append.go:5:5
65 . . . . . . Tok: =
66 . . . . . . Rhs: []ast.Expr (len = 1) {
67 . . . . . . . 0: *ast.CallExpr {
68 . . . . . . . . Fun: *ast.Ident {
69 . . . . . . . . . NamePos: append.go:5:7
70 . . . . . . . . . Name: "append"
71 . . . . . . . . }
72 . . . . . . . . Lparen: append.go:5:13
73 . . . . . . . . Args: []ast.Expr (len = 2) {
74 . . . . . . . . . 0: *ast.Ident {
75 . . . . . . . . . . NamePos: append.go:5:14
76 . . . . . . . . . . Name: "s2"
77 . . . . . . . . . . Obj: *(obj @ 32)
78 . . . . . . . . . }
79 . . . . . . . . . 1: *ast.BasicLit {
80 . . . . . . . . . . ValuePos: append.go:5:18
81 . . . . . . . . . . Kind: INT
82 . . . . . . . . . . Value: "100"
83 . . . . . . . . . }
84 . . . . . . . . }
85 . . . . . . . . Ellipsis: -
86 . . . . . . . . Rparen: append.go:5:21
87 . . . . . . . }
88 . . . . . . }
89 . . . . . }
90 . . . . }
91 . . . . Rbrace: append.go:6:1
92 . . . }
93 . . }
94 . }
95 . Scope: *ast.Scope {
96 . . Objects: map[string]*ast.Object (len = 1) {
97 . . . "main": *(obj @ 11)
98 . . }
99 . }
100 . Unresolved: []*ast.Ident (len = 2) {
101 . . 0: *(obj @ 45)
102 . . 1: *(obj @ 68)
103 . }
104 }
- Package: append.go:1:1 表示解析出 package 在 1 行 1 列
- main 是一个 ast.Ident 在 1 行 9 列
- Decls 是一个 ast.Decl 数组,里面有一个元素是一个 ast.FuncDecl 名称叫 main。
- ast.FuncType 表示是一个函数类型,ast.FieldList 为空左括号"("在 3 行 10 列,右括号")"在 3 行 11 列。
- 省略号…………
- (obj @ 7) 这里的 obj @ 没什么意思就是添加的打印信息,后面 7 指的是这个 ast.Object 对象在 ast 树的行数。
- Unresolved 表示在本文件中被引用,但是没有在本文件中定义
github 上有人提供了工具goast-viewer,可视化地将打印出语法树看起来更加直观。
2.3 类型检查(Type Checking)
Go 作为一种强类型编程语言,不仅有静态类型检查,而且有动态类型检查来保证类型的安全。Go 的类型检查代码位于src/cmd/compile/internal/typecheck IR node 有目前有 152 种 ops,我们挑 OAPPEND 和 OMAKE 这两种比较复杂的来分析一下:
// names
ONAME // var or func name
// Unnamed arg or return value: f(int, string) (int, error) { etc }
// Also used for a qualified package identifier that hasn't been resolved yet.
ONONAME
OTYPE // type name
OLITERAL // literal
ONIL // nil
// expressions
OADD // X + Y
OSUB // X - Y
OOR // X | Y
OXOR // X ^ Y
OADDSTR // +{List} (string addition, list elements are strings)
OADDR // &X
OANDAND // X && Y
OAPPEND // append(Args); after walk, X may contain elem type descriptor
OBYTES2STR // Type(X) (Type is string, X is a []byte)
OBYTES2STRTMP // Type(X) (Type is string, X is a []byte, ephemeral)
…………
OMAKE // make(Args) (before type checking converts to one of the following)
OMAKECHAN // make(Type[, Len]) (type is chan)
OMAKEMAP // make(Type[, Len]) (type is map)
OMAKESLICE // make(Type[, Len[, Cap]]) (type is slice)
OMAKESLICECOPY // makeslicecopy(Type, Len, Cap) (type is slice; Len is length and Cap is the copied from slice)
…………
2.3.1 OAPPEND
case ir.OAPPEND:
n := n.(*ir.CallExpr)
return tcAppend(n)
append 是 go 的内置函数,所以它是一个 function call 的一个类型,然后就调用了 tcAppend 函数,我在下面函数添加了注释,说明该函数的功能。
// tcAppend typechecks an OAPPEND node.
func tcAppend(n *ir.CallExpr) ir.Node {
typecheckargs(n)
args := n.Args
// 注释1: 首先检查参数个数,必须大于1
if len(args) == 0 {
base.Errorf("missing arguments to append")
n.SetType(nil)
return n
}
// 注释2: 获取第一个参数的类型,
t := args[0].Type()
if t == nil {
n.SetType(nil)
return n
}
n.SetType(t)
// 注释3: 类型必须要为slice
if !t.IsSlice() {
if ir.IsNil(args[0]) {
base.Errorf("first argument to append must be typed slice; have untyped nil")
n.SetType(nil)
return n
}
base.Errorf("first argument to append must be slice; have %L", t)
n.SetType(nil)
return n
}
// 注释4: ..., 必须要为2个参数,且...必须是第二个参数
if n.IsDDD {
if len(args) == 1 {
base.Errorf("cannot use ... on first argument to append")
n.SetType(nil)
return n
}
if len(args) != 2 {
base.Errorf("too many arguments to append")
n.SetType(nil)
return n
}
if t.Elem().IsKind(types.TUINT8) && args[1].Type().IsString() {
args[1] = DefaultLit(args[1], types.Types[types.TSTRING])
return n
}
args[1] = AssignConv(args[1], t.Underlying(), "append")
return n
}
as := args[1:]
for i, n := range as {
if n.Type() == nil {
continue
}
as[i] = AssignConv(n, t.Elem(), "append")
types.CheckSize(as[i].Type()) // ensure width is calculated for backend
}
return n
}
2.3.2 OMAKE
与 append 函数类似,内置函数 make 也是一个 function call 的一个类型,然后就调用了 tcMake 函数,函数定义如下:
// tcMake typechecks an OMAKE node.
func tcMake(n *ir.CallExpr) ir.Node {
args := n.Args
if len(args) == 0 {
base.Errorf("missing argument to make")
n.SetType(nil)
return n
}
n.Args = nil
l := args[0]
l = typecheck(l, ctxType)
t := l.Type()
if t == nil {
n.SetType(nil)
return n
}
i := 1
var nn ir.Node
switch t.Kind() {
default:
base.Errorf("cannot make type %v", t)
n.SetType(nil)
return n
case types.TSLICE:
if i >= len(args) {
base.Errorf("missing len argument to make(%v)", t)
n.SetType(nil)
return n
}
l = args[i]
i++
l = Expr(l)
var r ir.Node
if i 与 append 函数类似,内置函数 make 也是一个 function call 的一个类型,然后就调用了 tcMake 函数。因为 slice、map、chan 都用同一个内置函数 make 去创建,在类型检查阶段根据具体的类型去创建对象。
2.4 IR construction&优化
首先看一段简单的代码 sum.go 如下:
package main
func main() {
a := 1
b := 2
if true {
sum(a, b)
}
}
func sum(a, b int) {
println(a + b)
}
通过命令 go tool compile -W sum.go 可以生成 compiler 自己使用的 Abstract Syntax Tree ,我截取其中一段:
before walk main
. DCL # sum.go:4:2
. . NAME-main.a esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:4:2
. AS Def tc(1) # sum.go:4:4
. . NAME-main.a esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:4:2
. . LITERAL-1 int tc(1) # sum.go:4:7
. DCL # sum.go:5:2
. . NAME-main.b esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:5:2
. AS Def tc(1) # sum.go:5:4
. . NAME-main.b esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:5:2
. . LITERAL-2 int tc(1) # sum.go:5:7
. IF # sum.go:6:2
. IF-Cond
. . LITERAL-true bool tc(1) # sum.go:6:5
. IF-Body
. . DCL # sum.go:7:9
. . . NAME-main.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:13,sum.go:7:9
. . DCL # sum.go:7:9
. . . NAME-main.b esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:16,sum.go:7:9
. . AS2 Def tc(1) # sum.go:7:9
. . AS2-Lhs
. . . NAME-main.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:13,sum.go:7:9
. . . NAME-main.b esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:16,sum.go:7:9
. . AS2-Rhs
. . . NAME-main.a esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:4:2
. . . NAME-main.b esc(no) Class:PAUTO Offset:0 OnStack Used int tc(1) # sum.go:5:2
. . INLMARK # +sum.go:7:9
. . PRINTN tc(1) # sum.go:11:9,sum.go:7:9
. . PRINTN-Args
. . . ADD int tc(1) # sum.go:11:12,sum.go:7:9
. . . . NAME-main.a esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:13,sum.go:7:9
. . . . NAME-main.b esc(no) Class:PAUTO Offset:0 InlFormal OnStack Used int tc(1) # sum.go:10:16,sum.go:7:9
. . LABEL main..i0 # sum.go:7:9
上述已经是经过 inline 优化后的 go tool compile -W -l sum.go 可以输出未经过 inline 优化前的代码,比较一下:

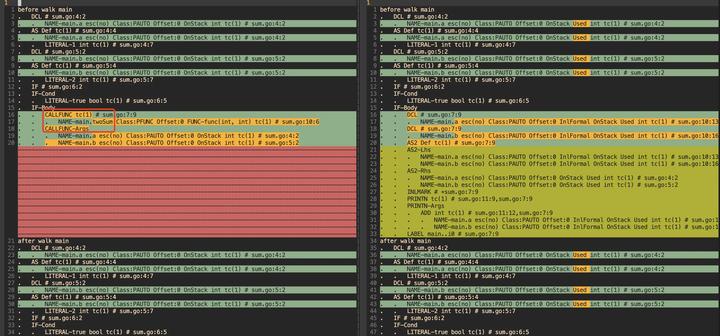
左边为优化前的代码,可以看到还有 CALL FUNC :twoSum,而右边就已经没有这个函数调用了,取而代之的是这个函数的展开。
2.4.1 Walk
walk 是 IR construction 的最后一个步骤,它的代码位于walk,主要有两个目的:
- 将复杂的语句分解为一些单独简单的语句,其中可能会引入一些临时变量。
- 将 Go 的一些高级的语法糖结构,脱糖为一些比较原始的结构。比如:将 switch 语句变成二分查找或者跳表,map 和 chan 的操作由 runtime 的 call 函数替代。
一开始提出的第二个问题在这里也可以得到答案,在 walk 这步,如果需要的 cap 大于原来的 cap,先进行 growslice,也就是我们在汇编代码里面看到的。
// expand append(l1, l2...) to
//
// init {
// s := l1
// newLen := s.len + l2.len
// // Compare as uint so growslice can panic on overflow.
// if uint(newLen) 2.4.2 SSA
Static Single Assignment (SSA) 是一种具有特定属性的低级别中间表示(IR),可以轻松的执行各种优化,并最终从 SSA 格式,生成机器代码。它的代码位于ssa
在生成 SSA 的过程中,进行了死代码消除,去除未使用的分支,用常量替换一些表达式,优化乘法和浮点数运算,某些 case 的特殊函数编译器会用高度优化的代码去替换。某些节点也被降级为更简单的组件,以便编译器的其余部分可以使用它们。 例如,copy builtin 被 memory moves 取代,range loops 被重写为 for loops。
命令 GOSSAFUNC=main go tool compile sum.go 会生成一个 html 文档,我们通过上面 sum.go 详细看下这个过程:

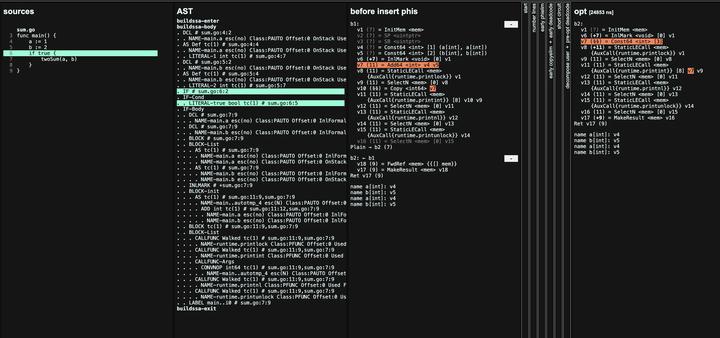
在我们的示例中,不必要的 if 判断在 ssa 的第一阶段之前就优化掉了,同时 twoSum 函数已经内联了。由于 a 和 b 在编译时已知,编译器可以计算最终结果并将变量标记为不再需要。 在上面的 opt 阶段我们发现 a , b 已经看不见了。
经过几十轮的优化,最终生成的汇编代码如下:

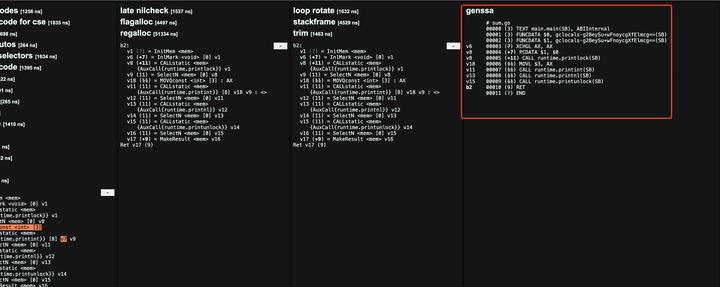
2.5 机器代码生成
在 SSA 生成阶段结束时,Go 函数已转换为一系列 obj.Prog 指令。 这些被传递给汇编程序(cmd/internal/obj),汇编程序将它们转换为机器代码并写出最终的目标文件。 目标文件还将包含反射数据、导出数据和调试信息。
机器代码的生成跟 cpu 架构和指令集有密切的关系,Go 现在已经支持所有主流的 cpu 架构
2.5.1 Go 支持的主流 cpu 架构
1、X86 架构,采用 CISC 指令集(复杂指令集计算机),程序的各条指令是按顺序串行执行的,每条指令中的各个操作也是按顺序串行执行的。
2、ARM 架构,是一个 32 位的精简指令集(RISC)架构。
3、RISC-V 架构,是基于精简指令集计算(RISC)原理建立的开放指令集架构,开源发展迅速
4、MIPS 架构,是一种采取精简指令集(RISC)的处理器架构,可支持高级语言的优化执行。
5、PowerPC 是美国 IBM 公司一种基于精简指令集合 (RISC)的处理器架构
6、LoongArch 龙芯是中国基于精简指令集计算(RISC)原理建立的指令集架构,Go1.19 以上支持
此外也支持 IBM(z) 系列 s390x 架构和 wsam 字节码。
2.5.2 代码生成
入口代码:Compile
// Compile builds an SSA backend function,
// uses it to generate a plist,
// and flushes that plist to machine code.
// worker indicates which of the backend workers is doing the processing.
func Compile(fn *ir.Func, worker int) {
f := buildssa(fn, worker)
// Note: check arg size to fix issue 25507.
if f.Frontend().(*ssafn).stksize >= maxStackSize || f.OwnAux.ArgWidth() >= maxStackSize {
largeStackFramesMu.Lock()
largeStackFrames = append(largeStackFrames, largeStack{locals: f.Frontend().(*ssafn).stksize, args: f.OwnAux.ArgWidth(), pos: fn.Pos()})
largeStackFramesMu.Unlock()
return
}
pp := objw.NewProgs(fn, worker)
defer pp.Free()
genssa(f, pp)
// Check frame size again.
// The check above included only the space needed for local variables.
// After genssa, the space needed includes local variables and the callee arg region.
// We must do this check prior to calling pp.Flush.
// If there are any oversized stack frames,
// the assembler may emit inscrutable complaints about invalid instructions.
if pp.Text.To.Offset >= maxStackSize {
largeStackFramesMu.Lock()
locals := f.Frontend().(*ssafn).stksize
largeStackFrames = append(largeStackFrames, largeStack{locals: locals, args: f.OwnAux.ArgWidth(), callee: pp.Text.To.Offset - locals, pos: fn.Pos()})
largeStackFramesMu.Unlock()
return
}
pp.Flush() // assemble, fill in boilerplate, etc.
// fieldtrack must be called after pp.Flush. See issue 20014.
fieldtrack(pp.Text.From.Sym, fn.FieldTrack)
}
上面的 pp.Flush根据 ssa 生成的 plist 调用 Flushplist去生成对应硬件架构指令的机器码。
…………
// Turn functions into machine code images.
for _, s := range text {
mkfwd(s)
if ctxt.Arch.ErrorCheck != nil {
ctxt.Arch.ErrorCheck(ctxt, s)
}
linkpatch(ctxt, s, newprog)
ctxt.Arch.Preprocess(ctxt, s, newprog)
ctxt.Arch.Assemble(ctxt, s, newprog)
if ctxt.Errors > 0 {
continue
}
linkpcln(ctxt, s)
if myimportpath != "" {
ctxt.populateDWARF(plist.Curfn, s, myimportpath)
}
}
…………
2.6 小结
到目前为止,文中前面提到的两个疑问成功得到解决,slice 的内存增长算法和内存对齐规则。以及在编译的过程中,如何将 builtin 的 append 函数,一步步成功替换成 runtime.growslice 函数的。
3、总结
本文从 slice 的内存增长问题开始,分析了 Go 内存内配的对齐规则和 Go 语言的编译过程。下篇会给大家介绍下分析下 Go 的汇编和内存管理,敬请期待。
参考资料
https://go.dev/src/cmd/compile/README

