
一、常见服务器问题定位:
1、常见服务器问题:
日常开发中,我们常见的服务器问题主要可以归类为一下几种::
CPU过载问题
内存过高问题
磁盘IO问题
网络问题
2、服务器问题定位总体思路:
当服务器出现问题时,我们一般可以按照以下思路进行定位
① 如果最近有版本发布,则先从代码提交记录中分析最新版本代码是否存在问题
② 使用 ps、top等命令分析线程状态
③ 先将出现异常的服务器下线并保留服务器环境,接着使用 jstack 导出线程快照信息以及使用 jmap 导出堆栈内存日志进行分析,该命令会会线上服务器性能造成影响,所以执行前先下线服务器防止对用户造成影响
对于磁盘 IO 问题以及网络问题,我们一般可以很快定位出来,所以这篇文章中就不展开讨论了,下面我们主要介绍下如何定位与解决 CPU飙高问题 以及 Java 内存占用过高的问题。
二、CPU飙高问题定位:
1、 Java 有哪些CPU密集操作:
- 频繁的GC: 如果访问量很高,内存分配太快,可能会导致频繁的GC甚至FGC,从而导致CPU飙升
- 线程上下文切换:大量线程的状态在 Blocked(锁定等待,IO等待等)和 Running 之间发生变化。当锁争用激烈时,这种情况很容易发生。
- 有些线程正在执行非阻塞操作,如死循环
- 序列化和反序列化
- 正则表达式
2、Java程序CPU飙高定位步骤:
(1)使用 top 命令找到最耗CPU的线程ID :
(2)将最耗CPU的线程ID转成16进制,因为线程快照文件中的线程编号是以16进制记录的:
(3)将有问题的服务器下线,接着使用 jstack 导出线程快照信息,查看第(2)步中找出的线程ID正在进行什么操作:
注:出现以下问题解决
出错原因:jstack命令使用了jstack +线程号(不是具体线程号,而是java进程号),具体使用如下:
top命令查看CPU占用情况
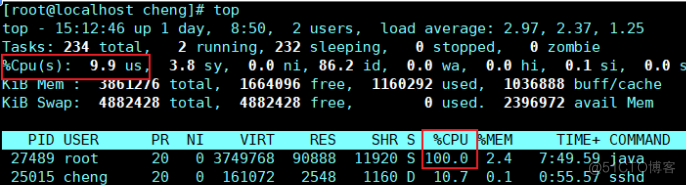
top -h 查看java进程cpu情况, top界面下按大写H 查看每个线程CPU情况27489
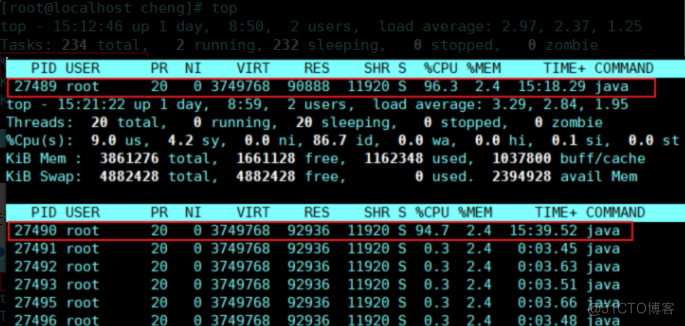
看到27489 java进程中27490线程占用高额CPU
计算27490的十六进制表示,得到6b62 printf ‘%x n’ PID
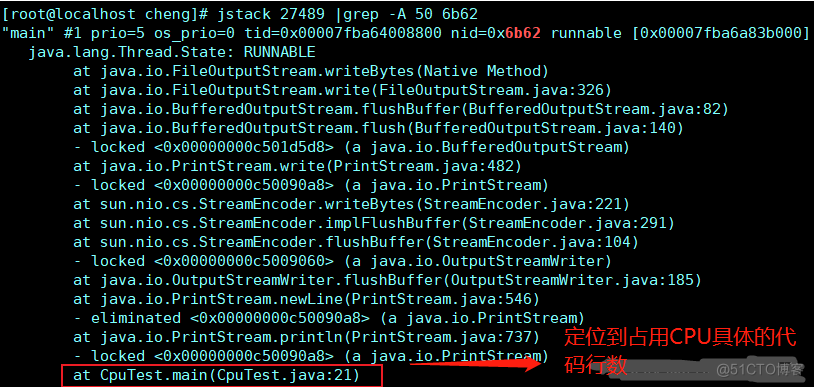
使用jstack查看进程号为27489的Java应用中十六进制线程号为6b62的堆栈信息(开始用的是27490进程号)
三、Java内存占用过高的定位办法:
内存过高一般是内存泄漏、内存溢出导致的。首先检查线程快照日志是否有异常,接着使用 jmap -dump 导出堆栈日志后,查看是什么对象在占用空间,常见的是代码中的误操作或者不严谨操作导致的,还有可能是线程创建过多导致
四、jstack线程快照文件分析说明:
4.1、线程快照状态 stacktrace 说明:
4.1.1、Deadlock:死锁线程,多个线程相互占有资源并一直相互等待导致阻塞的情况。
4.1.2、runnable:表示线程具备所有运行条件,或者正在执行中的线程状态
4.1.3、waiting for monitor entry 和 in Object.wait():Monitor 是 Java 的 synchronized 锁机制实现线程互斥与协作的主要手段,可以看成是对象或Class锁,每个对象有且仅有一个 monitor,每个Monitor在同一时刻只能被一个线程拥有,该线程就是 “Active Thread”,而其它线程都是 “Waiting Thread”,“Waiting Thread” 存放在两个集合 “EntrySet” 和 “WaitSet” 里面等候。在 “EntrySet” 中等待的线程状态是 “Waiting for monitor entry”,而在 “WaitSet” 中等待的线程状态是 “in Object.wait()”。被 synchronized 保护起来的代码段为临界区,当一个线程申请进入临界区时,它就进入了 “EntrySet” 队列,当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象的 wait() 方法,放弃了 Monitor,进入 “WaitSet” 队列,只有当别的线程在该对象上调用了 notify() 或者 notifyAll() ,“WaitSet”队列中线程才得到机会去竞争。
4.1.4、waiting on condition:等待资源或等待某个条件的发生,具体需要结合 stacktrace 来分析:
(1)最常见的就是线程处于 sleep 状态,等待被唤醒。
(2)常见的情况还有等待网络IO,在未引入NIO前,对于每个网络连接,都有一个对应的线程来处理网络的读写操作,即使没有可读写的数据,线程仍然阻塞在读写操作上。在引入NIO后,如果发现大量的线程都处于网络阻塞状态,那可能是一个网络瓶颈的征兆,因为网络阻塞导致线程无法执行:
- 一种情况是网络非常忙,几乎消耗了所有的带宽,仍然有大量数据等待网络读写;
- 另一种情况也可能是网络空闲,但由于路由等问题,导致包无法正常的到达。
4.1.5、Blocked:线程阻塞,是指当前线程执行过程中,所需要的资源长时间等待却一直未能获取到,被容器的线程管理器标识为阻塞状态,可以理解为等待资源超时的线程。
4.2、在线程快照文件中需要重点关注现象:
(1)持续 runnable 运行的 IO 线程:
IO 操作是可以以 RUNNABLE 状态达成阻塞,例如:数据库死锁、网络读写,所以需要特别注意对 IO 线程的真实状态的分析,一般来说,被捕捉到 RUNNABLE 的 IO 调用,都是有问题的。
以下堆栈显示:线程状态为 RUNNABLE,调用栈在 SocketInputStream 或 SocketImpl 上,socketRead0 等方法。 调用栈包含了jdbc相关的包,很可能发生了数据库死锁
以下堆栈是线程池的情况:
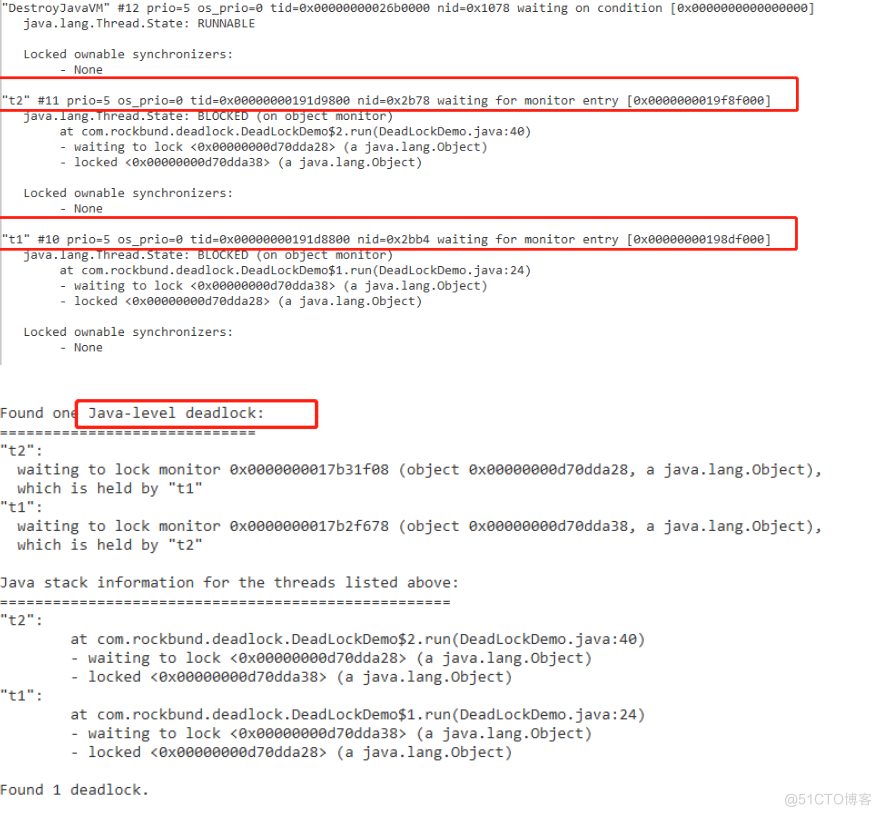
(2)死锁现象:
jstack 会帮助我们分析出死锁的情况,可以直接定位,具体情况分析处理就行了
(3)死循环:
死循环状态的表现形式为,CPU飙高,查看线程运行情况发现某个线程,占用很久的CPU运行时间片段以及较高CPU使用率,打印线程栈日志发现某个线程一直处于Runnable状态
(4)线程上下文切换过于频繁:
① JVM 有一个线程调度器,用来确定哪个时刻运行哪个线程,调度器主要有两种:抢占式线程调度器和协作式线程调度器。每个线程可能会有自己的优先级,但是优先级并不意味着高优先级的线程一定会被调度,而是由 CPU 随机选择
- 抢占式线程调度:线程在执行自己的任务时,虽然任务还没有执行完,但是 CPU 会迫使它暂停,让其它线程占有 CPU 的使用权。
- 协作式线程调度:线程在执行自己的任务时,不允许被中途打断,一定等当前线程将任务执行完毕后才会释放对 CPU 的占有,其它线程才可以抢占该cpu。
② 该类问题的表现形式经常为,CPU与内存统统飙高,jstack 中存在大量线程处于 waiting,timed_waiting 状态,因为线程的执行调度协调是CPU来处理的,CPU负责给每个线程分配可执行片段,频繁的处理这些线程的调度,就会造成CPU的负载过高
(5)大量GC线程:
该类问题的表现形式为 jstack 中存在大量GC线程,消耗CPU最高的是GC线程,也就是经常说的频繁GC:
文章来源于互联网:堆栈分析-常见服务器问题

