
总结一下常见Go语言的面试题
new 和 make 的区别
首先我们得知道,Go分为数据类型分为值类型和引用类型,其中
值类型是 int、float、string、bool、struct和array,它们直接存储值,分配栈的内存空间,它们被函数调用完之后会释放
引用类型是 slice、map、chan和值类型对应的指针 它们存储是一个地址(或者理解为指针),指针指向内存中真正存储数据的首地址,内存通常在堆分配,通过GC回收
区别
new 的参数要求传入一个类型,而不是一个值,它会申请该类型的内存大小空间,并初始化为对应的零值,返回该指向类型空间的一个指针
make 也用于内存分配,但它只用于引用对象 slice、map、channel的内存创建,返回的类型是类型本身
值传递和指针传递有什么区别
值传递:会创建一个新的副本并将其传递给所调用函数或方法 指针传递:将创建相同内存地址的新副本
需要改变传入参数本身的时候用指针传递,否则值传递
另外,如果函数内部返回指针,会发生内存逃逸
聊聊内存逃逸分析
Go的逃逸分析是一种确定指针动态范围的方法,可以分析程序在哪些可以访问到指针,它涉及到指针分析和状态分析。
当一个变量(或对象)在子程序中被分配时,一个指向变量的指针可能逃逸到其它程序,或者去调用子程序。 如果使用尾递归优化(通常函数式编程是需要的),对象也可能逃逸到被调用程序中。如果一个子程序分配一个对象并返回一个该对象的指针,该对象可能在程序中的任何一个地方都可以访问。
如果指针存储在全局变量或者其它数据结构中,它们也可能发生逃逸,这种情况就是当前程序的指针逃逸。逃逸分析需要确定指针所有可以存储的地方,保证指针的生命周期只在当前进程或线程中。
导致内存逃逸的情况比较多(有些可能官方未能够实现精确的逃逸分析情况的bug),通常来讲就是如果变量的作用域不会扩大并且行为或者大小能够在其编译时确定,一般情况下都分配栈上,否则就可能发生内存逃逸到堆上。
引用内存逃逸的典型情况:
- 在函数内部返回把局部变量指针返回 局部变量原本应该在栈中分配,在栈中回收。但是由于返回时被外部引用,因此生命周期大于栈,则溢出
- 发送指针或带有指针的值到channel中 在编译时,是没办法知道哪个 goroutine 会在 channel上接受数据,所以编译器没办法知道变量什么时候释放。
- 在一个切片上存储指针或带指针的值 一个典型的例子就是 []*string,这会导致切片的内容逃逸,尽管其后面的数组在栈上分配,但其引用值一定是在堆上、
- slice 的背后数组被重新分配了 因为 append 时可能会超出其容量( cap )。 slice 初始化的地方在编译时是可以知道的,它最开始会在栈上分配。如果切片背后的存储要基于运行时的数据进行扩充,就会在堆上分配。
- 在 interface 类型上调用方法 在 interface 类型上调用方法都是动态调度的 —— 方法的真正实现只能在运行时知道。想像一个 io.Reader 类型的变量 r , 调用 r.Read(b) 会使得 r 的值和切片b 的背后存储都逃逸掉,所以会在堆上分配。
了解过golang的内存管理吗
内存池概述
Go语言的内存分配器采用了跟 tcmalloc 库相同的实现,是一个带内存池的分配器,底层直接调用操作系统的 mmpa 等函数。
作为一个内存池,它的基本部分包括以下几部分:
- 首先,它会想操作系统申请大块内存,自己管理这部分内存
- 然后,它是一个池子,当上层释放内存时它不实际归还给操作系统,而是放回池子重复利用
- 接着,内存管理中必然会考虑的就是内存碎片问题,如果尽量避免内存碎片,提高内存利用率,像操作系统中的首次适应,最佳适应,最差适应,伙伴算法都是一些相关的知识背景。
- 另外,Go语言是一个支持 goroutine 这种多线程的语言,所以它的内存管理系统必须要考虑在多线程下的稳定性和效率问题。
在多线程方面
很自然的做法就是每条线程都有自己的本地的内存,然后有一个全局的分配链,当某个线程中的内存不足后就向全局分配链中申请内存。这样就避免了多线程同时访问共享变量的加锁。
在避免内存碎片方面,大块内存直接按页为单位分配,小块内存会切成各种不同的固定大小的块,申请做任意字节内存时会向上取整到最接近的块,将整块分配给申请者以避免随意切割。
在避免内存碎片方面
大块内存直接按页为单位分配,小块内存会切成各种不同的固定大小的块,申请做任意字节内存时会向上取整到最接近的块,将整块分配给申请者以避免随意切割。
Go语言中为每个系统线程分配一个本地的 MCahe,少量的地址分配就直接从 MCache 中分配,并且定期做垃圾回收,将线程的 MCache 中的空闲内存返回给全局控制堆。小于 32K为小对象,大对象直接从全局控制堆上以页(4k)为单位进行分配,也就是说大对象总是以页对齐的。一个页可以存入一些相同大小的小对象,小对象从本地内存链表中分配,大对象从中心内存对分配。
大约有 100 种内存块类别,每一个类别都有自己对象的空闲链表。小于 32KB 的内存分配被向上取整到对应的尺寸类别,从相应的空闲链表中分配。一页内存只可以被分裂成同一种尺寸类别的对象,然后由空间链表分配管理器。
大约有 100 种内存块类别,每一个类别都有自己对象的空闲链表。小于 32kB 的内存分配被向上取整到对应的尺寸类别,从相应的空闲链表中分配。一页内存只可以被分裂成同一种尺寸类别的对象,然后由空闲链表分配器管理。
分配器的数据结构包括: FixAlloc:固定大小(128kB)的对象的空闲链分配器,被分配器用于管理存储; MHeap:分配堆,按页的粒度进行管理(4kB); MSpan:一些由 MHeap 管理的页; MCentral:对于给定尺寸类别的共享的 free list; * MCache:用于小对象的每 M 一个的 cache。
我们可以将Go语言的内存管理看成一个两级的内存管理结构 MHeap 和 MCache。上面一级管理的基本单位是页,用于分配大对象,每次分配都是若干连续的页,也就是若干个 4KB 的大小。使用的数据结构是 MHeap 和 MSpan,用 BestFit 算法做分配,用位示图做回收。下面一级管理的基本单位是不同类型的固定大小的对象,更像一个对象池而不是内存池,用引用计数做回收。下面这一级使用的数据结构是 MCache。
线程有几种模型?Goroutine 的原理你了解过吗,将一下实现和原理
线程模型有n
- 内核线程模型
- 用户级线程模型
- 混合型线程模型
Linux历史上线程的3种实现模型: 线程的实现曾有3种模型:
- 多对一(M:1)的用户级线程模型
- 一对一(1:1)的内核级线程模型
- 多对多(M:N)的两级线程模型
goroutine的原理
基于CSP并发模型开发了GMP调度器,其中
- G(Goroutine) : 每个 Goroutine 对应一个 G 结构体,G 存储 Goroutine 的运行堆栈、状态以及任务函数
- M(Machine): 对OS内核级线程的封装,数量对应真实的CPU数(真正干活的对象).
- P (Processor): 逻辑处理器,即为G和M的调度对象,用来调度G和M之间的关联关系,其数量可通过 GOMAXPROCS()来设置,默认为核心数。
在单核情况下,所有Goroutine运行在同一个线程(M0)中,每一个线程维护一个上下文(P),任何时刻,一个上下文中只有一个Goroutine,其他Goroutine在runqueue中等待。
一个Goroutine运行完自己的时间片后,让出上下文,自己回到runqueue中(如下图所示)。

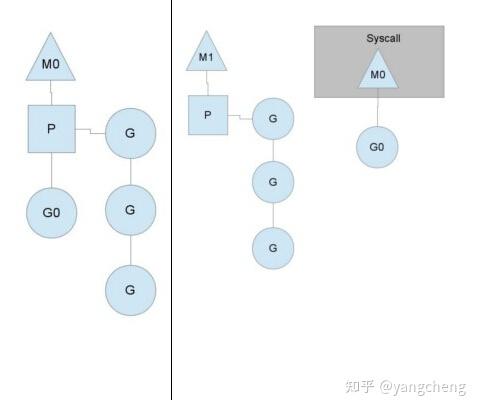
当正在运行的G0阻塞的时候(可以需要IO),会再创建一个线程(M1),P转到新的线程中去运行。
当M0返回时,它会尝试从其他线程中“偷”一个上下文过来,如果没有偷到,会把Goroutine放到Global runqueue中去,然后把自己放入线程缓存中。 上下文会定时检查Global runqueue。
goroutine的优势
- 上下文切换代价小:从GMP调度器可以看出,避免了用户态和内核态线程切换,所以上下文切换代价小
- 内存占用少:线程栈空间通常是 2M,Goroutine 栈空间最小 2K;
goroutine 什么时候发生阻塞
- channel 在等待网络请求或者数据操作的IO返回的时候会发生阻塞
- 发生一次系统调用等待返回结果的时候
- goroutine进行sleep操作的时候
在GPM调度模型,goroutine 有哪几种状态?线程呢?
有9种状态
- _Gidle:刚刚被分配并且还没有被初始化
- _Grunnable:没有执行代码,没有栈的所有权,存储在运行队列中
- _Grunning:可以执行代码,拥有栈的所有权,被赋予了内核线程 M 和处理器 P
- _Gsyscall:正在执行系统调用,拥有栈的所有权,没有执行用户代码,被赋予了内核线程 M 但是不在运行队列上
- _Gwaiting:由于运行时而被阻塞,没有执行用户代码并且不在运行队列上,但是可能存在于 Channel 的等待队列上
- _Gdead:没有被使用,没有执行代码,可能有分配的栈
- _Gcopystack:栈正在被拷贝,没有执行代码,不在运行队列上
- _Gpreempted:由于抢占而被阻塞,没有执行用户代码并且不在运行队列上,等待唤醒
- _Gscan:GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在
去抢占 G 的时候,会有一个自旋和非自旋的状态
线程和协程内存多少
线程一般是2M,协程一般是2K
如果 goroutine 一直占用资源怎么办,GMP模型怎么解决这个问题
如果有一个goroutine一直占用资源的话,GMP模型会从正常模式转为饥饿模式,通过信号协作强制处理在最前的 goroutine 去分配使用
如果若干个线程发生OOM,会发生什么?Goroutine中内存泄漏的发现与排查?项目出现过OOM吗,怎么解决
线程
如果线程发生OOM,也就是内存溢出,发生OOM的线程会被kill掉,其它线程不受影响。
Goroutine中内存泄漏的发现与排查
go中的内存泄漏一般都是goroutine泄露,就是goroutine没有被关闭,或者没有添加超时控制,让goroutine一只处于阻塞状态,不能被GC。
场景
在Go中内存泄露分为暂时性内存泄露和永久性内存泄露
暂时性内存泄露
- 获取长字符串中的一段导致长字符串未释放
- 获取长slice中的一段导致长slice未释放
- 在长slice新建slice导致泄漏
string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏
永久性内存泄露
- goroutine永久阻塞而导致泄漏
- time.Ticker未关闭导致泄漏
- 不正确使用Finalizer导致泄漏
使用pprof排查
Go的垃圾回收算法
Go 1.5 后,采取的是并发标记和并发清除,三色标记的算法
Go 中的 gc 基本上是标记清除的过程:


Go 的垃圾回收是基于标记清除算法,这种算法需要进行 STW (stop the world),这个过程就是会导致程序是卡顿的,频繁的 GC 会严重影响程序性能
Go 在此基础上进行了改进,通过三色标记清除扫法与写屏障来减少 STW 的时间
GC 的过程一共分为四个阶段:
- 栈扫描(STW),所有对象开始都是白色
- 从 root 开始找到所有可达对象(所有可以找到的对象),标记灰色,放入待处理队列
- 遍历灰色对象队列,将其引用对象标记为灰色放入待处理队列,自身标记为黑色
- 清除(并发)循环步骤3 直到灰色队列为空为止,此时所有引用对象都被标记为黑色,所有不可达的对象依然为白色,白色的就是需要进行回收的对象。三色标记法相对于普通标记清除,减少了 STW 时间。这主要得益于标记过程是 “on-the-fly”的,在标记过程中是不需要 STW的,它与程序是并发执行的,这就大大缩短了 STW 的时间。
Go GC 优化的核心就是尽量使得 STW(Stop The World) 的时间越来越短。
写屏障:
当标记和程序是并发执行的,这就会造成一个问题. 在标记过程中,有新的引用产生,可能会导致误清扫.
清扫开始前,标记为黑色的对象引用了一个新申请的对象,它肯定是白色的,而黑色对象不会被再次扫描,那么这个白色对象无法被扫描变成灰色、黑色,它就会最终被清扫,而实际它不应该被清扫.
这就需要用到屏障技术,golang采用了写屏障,其作用就是为了避免这类误清扫问题. 写屏障即在内存写操作前,维护一个约束,从而确保清扫开始前,黑色的对象不能引用白色对象.
Go数据竞争怎么解决
Data Race 问题可以使用互斥锁解决,或者也可以通过CAS无锁并发解决
中使用同步访问共享数据或者CAS无锁并发是处理数据竞争的一种有效的方法.
golang在1.1之后引入了竞争检测机制,可以使用 go run -race 或者 go build -race来进行静态检测。
其在内部的实现是,开启多个协程执行同一个命令, 并且记录下每个变量的状态.
竞争检测器基于C/C++的ThreadSanitizer运行时库,该库在Google内部代码基地和Chromium找到许多错误。这个技术在2012年九月集成到Go中,从那时开始,它已经在标准库中检测到42个竞争条件。现在,它已经是我们持续构建过程的一部分,当竞争条件出现时,它会继续捕捉到这些错误。
竞争检测器已经完全集成到Go工具链中,仅仅添加-race标志到命令行就使用了检测器。
$ go test -race mypkg // 测试包
$ go run -race mysrc.go // 编译和运行程序
$ go build -race mycmd // 构建程序
$ go install -race mypkg // 安装程序要想解决数据竞争的问题可以使用互斥锁sync.Mutex,解决数据竞争(Data race),也可以使用管道解决,使用管道的效率要比互斥锁高.
Go:反射之用字符串函数名调用函数
package main
import (
"fmt"
"reflect"
)
type Animal struct {
}
func (m *Animal) Eat() {
fmt.Println("Eat")
}
func main() {
animal := Animal{}
value := reflect.ValueOf(&animal)
f := value.MethodByName("Eat") //通过反射获取它对应的函数,然后通过call来调用
f.Call([]reflect.Value{})
}
开发用过gin框架吗?参数检验怎么做的?中间使怎么使用的
gin框架使用http://github.com/go-playground/validator进行参数校验 在 struct 结构体添加 binding tag,然后调用 ShouldBing 方法,下面是一个示例
type SignUpParam struct {
Age uint8 `json:"age" binding:"gte=1,lte=130"`
Name string `json:"name" binding:"required"`
Email string `json:"email" binding:"required,email"`
Password string `json:"password" binding:"required"`
RePassword string `json:"re_password" binding:"required,eqfield=Password"`
}
func main() {
r := gin.Default()
r.POST("/signup", func(c *gin.Context) {
var u SignUpParam
if err := c.ShouldBind(&u); err != nil {
c.JSON(http.StatusOK, gin.H{
"msg": err.Error(),
})
return
}
// 保存入库等业务逻辑代码...
c.JSON(http.StatusOK, "success")
})
_ = r.Run(":8999")
}
中间件使用use方法,Gin的中间件其实就是一个HandlerFunc,那么只要我们自己实现一个HandlerFunc,下面是一个示例
func costTime() gin.HandlerFunc {
return func(c *gin.Context) {
//请求前获取当前时间
nowTime := time.Now()
//请求处理
c.Next()
//处理后获取消耗时间
costTime := time.Since(nowTime)
url := c.Request.URL.String()
fmt.Printf("the request URL %s cost %vn", url, costTime)
}
}
以上我们就实现了一个Gin中间件,比较简单,而且有注释加以说明,这里要注意的是c.Next方法,这个是执行后续中间件请求处理的意思(含没有执行的中间件和我们定义的GET方法处理),这样我们才能获取执行的耗时。也就是在c.Next方法前后分别记录时间,就可以得出耗时。
goroutine的锁机制了解过吗?Mutex有哪几种模式?Mutex 锁底层如何实现
互斥锁的加锁是靠 sync.Mutex.Lock 方法完成的, 当锁的状态是 0 时,将 mutexLocked 位置成 1:
// Lock locks m.
// If the lock is already in use, the calling goroutine
// blocks until the mutex is available.
func (m *Mutex) Lock() {
// Fast path: grab unlocked mutex.
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Slow path (outlined so that the fast path can be inlined)
m.lockSlow()
}
Mutex:正常模式和饥饿模式
在正常模式下,锁的等待者会按照先进先出的顺序获取锁。
但是刚被唤起的 Goroutine 与新创建的 Goroutine 竞争时,大概率会获取不到锁,为了减少这种情况的出现,一旦 Goroutine 超过 1ms 没有获取到锁,它就会将当前互斥锁切换饥饿模式,防止部分 Goroutine 被饿死。
饥饿模式是在 Go 语言 1.9 版本引入的优化的,引入的目的是保证互斥锁的公平性(Fairness)。
在饥饿模式中,互斥锁会直接交给等待队列最前面的 Goroutine。新的 Goroutine 在该状态下不能获取锁、也不会进入自旋状态,它们只会在队列的末尾等待。
如果一个 Goroutine 获得了互斥锁并且它在队列的末尾或者它等待的时间少于 1ms,那么当前的互斥锁就会被切换回正常模式。
相比于饥饿模式,正常模式下的互斥锁能够提供更好地性能,饥饿模式的能避免 Goroutine 由于陷入等待无法获取锁而造成的高尾延时。
参考链接
- 一些可能的内存泄漏场景
- Golang面试问题汇总
- Golang 面试题搜集
- Go 为什么这么快 GPM模型简介
- Go语言内存分配器
- Go语言内存管理简述
- 分代收集算法、减少系统的停顿时间( STW )的算法(增量收集、分区算法)
- Go并发编程里的数据竞争以及解决之道
文章来源于互联网:Go语言面试问得最多的面试题

