
背景
并发情况下如果不能很好的管理线程或者线程下,当数量足够多的时候会导致服务器宕机,因此需要一个管理线程或者协程的技术-池化技术。池化技术有两个方面的优点,1、避免了每次使用创建线程或者不使用后销毁,这样会在创建销毁的时候消耗资源。2、由于池化技术限制了系统资源的大小,避免过多的资源导致机器宕机。
协程的简单介绍
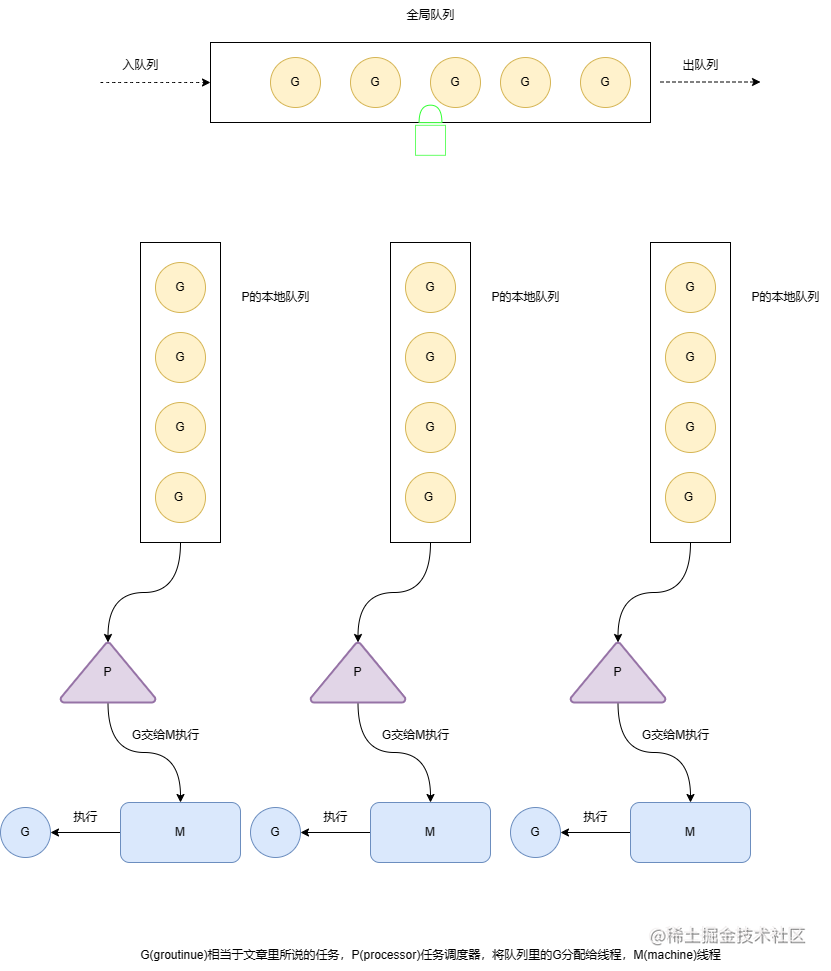
接下来简单介绍一下协程,之后再根据协程的特性去抽象出池化技术。话说在程序界没有什么是加一层不能解决的问题。由于线程的创建与销毁比较消耗系统资源,所以就根据复用线程的思想构建出了协程的概念,然而怎样才能复用线程呢,首先来分析在计算机中是怎样处理并发的,并发场景下,每个线程绑定一个任务,当任务执行时创建线程,当任务结束时销毁线程,这个时候线程和任务是1:1的关系,所以要想实现线程的复用必须到达到线程:任务=1:N,甚至是线程:任务=M:N(M
协程的使用
package main
import (
"fmt"
)
func A() {
fmt.Println("你好我是路飞")
}
func main() {
fmt.Println("你好我是艾斯")
go A()
fmt.Println("你好我是萨博")
}
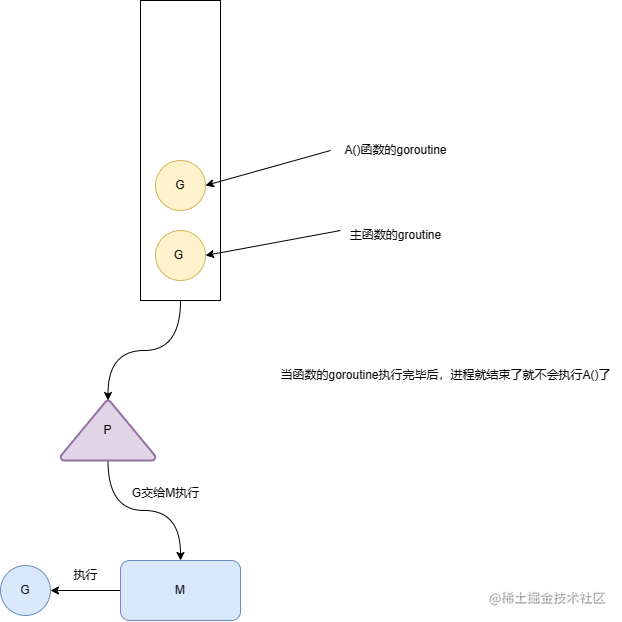
从这段程序中我们可以看出 go A()就是创建了一个groutine,并且将goroutine放入主线程的goroutine队列中(因为他们属于同一个线程),因此执行这段程序中你会看到如下结果
你好我是艾斯
你好我是萨博
那我为什么会出现这种问题呢,下面一个图就能让你明白其中的原理
下面我们为了让A()执行我们,让主函数阻塞等待A()执行完毕后再执行之后的逻辑。
package main
import (
"fmt"
"sync"
)
func A() {
fmt.Println("你好我是路飞")
}
func main() {
var wg sync.WaitGroup
fmt.Println("你好我是艾斯")
wg.Add(1)
go func() {
defer wg.Done()
A()
}()
wg.Wait() //等待子协程执行完毕
fmt.Println("你好我是萨博")
}
执行结果
你好我是艾斯
你好我是路飞
你好我是萨博
协程池的设计
虽然goroutine的创建与销毁消耗资源比较小,但是话说水滴石穿,当多个goroutine创建和销毁修会对系统产生比较大的影响,况且创建过多的goroutine会对计算机造成不必要的麻烦,所以我们就给goroutine造一个池子,使用完成就放回去,用的时候就从池子里取。
设计方案分析
实现gorutine有两种方案,1、给goroutine建立一个池子(线程池的思想)。2、一个goroutine执行一个任务队列(这一点与协程的实现有点类似),其实就是任务队列我们可以叫他任务池。由于goroutine只能通过关键字建立,而不能通过连接,所以我们使用第二种方案建立go协程池。
结构定义以及设计
任何计算机里面的建模都是要从属性(变量)和行为(方法)方面分析的,先定义出对象,然后定义对象之间的关系。首先要定义系统中的对象,协程池我们定义成pool,协程我们定义成worker(也就是协程),任务我们定义成task。
多个worker去执行任务队列里的任务(在gorountine里面使用循环取task执行,实现一个worker可以执行多个task,实现goroutine的复用)类似于消费者的概念,并且对worker大小进行限制。
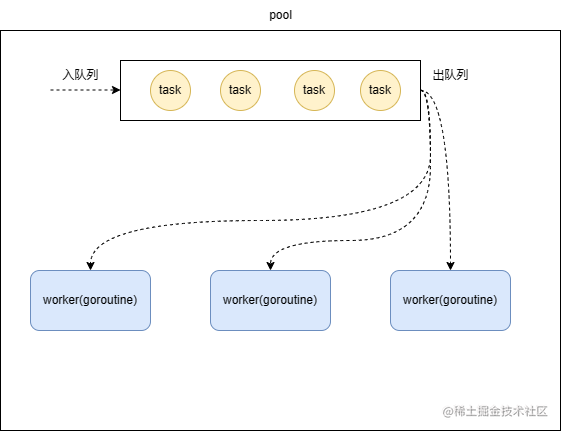
程序对象定义
task
func init() {
workerPool.New = newWorker
}
/*
*任务相关,使用实例池来达到task的复用
*/
type task struct {
ctx context.Context
f func()
next *task
}
// 任务池,复用task对象
var taskPool sync.Pool
func init() {
taskPool.New = newTask
}
// 清空任务内容
func (t *task) zero() {
t.ctx = nil
t.f = nil
t.next = nil
}
// 实现任务内容清空并放入对象池
func (t *task) Recycle() {
t.zero()
taskPool.Put(t)
}
// 创建一个空的task
func newTask() interface{} {
return &task{}
}
// 任务列表
type taskList struct {
sync.Mutex
taskHead *task
taskTail *task
}
worker
// worker实例池,目的实现worker的复用
var workerPool sync.Pool
type worker struct {
//worker关联的协程池
pool *pool
}
// 创建空worker
func newWorker() interface{} {
return &worker{}
}
// worker关联创建协程
func (w *worker) run() {
go func() {
for {
var t *task
//取出任务
w.pool.taskLock.Lock()
if w.pool.taskHead != nil {
t = w.pool.taskHead
w.pool.taskHead = w.pool.taskHead.next
atomic.AddInt32(&w.pool.taskCount, -1)
}
if t == nil {
// if there's no task to do, exit
w.close()
w.pool.taskLock.Unlock()
w.Recycle()
return
}
w.pool.taskLock.Unlock()
func() {
//错误处理
defer func() {
if r := recover(); r != nil {
if w.pool.panicHandler != nil {
w.pool.panicHandler(t.ctx, r)
} else {
msg := fmt.Sprintf("GOPOOL: panic in pool: %s: %v: %s", w.pool.name, r, debug.Stack())
logger.CtxErrorf(t.ctx, msg)
}
}
}()
//执行任务
t.f()
}()
//清空已经执行的任务,并放入任务池中
t.Recycle()
}
}()
}
// 关闭协程或者worker
func (w *worker) close() {
w.pool.decWorkerCount()
}
func (w *worker) zero() {
w.pool = nil
}
func (w *worker) Recycle() {
w.zero()
workerPool.Put(w)
}
pool
type pool struct {
//名称
name string
//容量,也就是goroutine的最大数量
capacity int32
//配置
config *Config
//整个协程池的任务队列的头指针与尾指针
taskHead *task
taskTail *task
//任务锁。保证任务相关操作的原子性
taskLock sync.Mutex
//任务数量
taskCount int32
//worker数量或者叫协程数量
workerCount int32
//当执行任务出现painc的处理
panicHandler func(context.Context, interface{})
}
// Pool 接口定义
type Pool interface {
//获取协程名称
Name() string
//设置容量大小
SetCap(cap int32)
//执行任务
Go(f func())
//执行任务并传入上线文
CtxGo(ctx context.Context, f func())
//设置panic处理逻辑
SetPanicHandler(f func(context.Context, interface{}))
//获取work也就是goroutine数量
WorkerCount() int32
}
func NewPool(name string, capacity int32, config *Config) Pool {
p := &pool{
name: name,
capacity: capacity,
config: config,
}
return p
}
// 获取协程池名称
func (p *pool) Name() string {
return p.name
}
// 设置容量
func (p *pool) SetCap(capacity int32) {
atomic.StoreInt32(&p.capacity, capacity)
}
// 传入任务,执行任务
func (p *pool) Go(f func()) {
p.CtxGo(context.Background(), f)
}
// 传入上线文执行任务
func (p *pool) CtxGo(ctx context.Context, f func()) {
//从实体池中获取未初始化的任务并赋值初始化
t := taskPool.Get().(*task)
t.ctx = ctx
t.f = f
//将任务加入任务队列中,并将任务数量+1
p.taskLock.Lock()
if p.taskHead == nil {
p.taskHead = t
p.taskTail = t
} else {
p.taskTail.next = t
p.taskTail = t
}
p.taskLock.Unlock()
atomic.AddInt32(&p.taskCount, 1)
//如果任务的数量大于配置的任务数量并且work数量大于配置数量,或者work数量为0,创建work(goroutine)
if (atomic.LoadInt32(&p.taskCount) >= p.config.ScaleThreshold && p.WorkerCount() .LoadInt32(&p.capacity)) || p.WorkerCount() == 0 {
p.incWorkerCount()
w := workerPool.Get().(*worker)
w.pool = p
w.run()
}
}
// 设置panic后的处理逻辑
func (p *pool) SetPanicHandler(f func(context.Context, interface{})) {
p.panicHandler = f
}
// 查询work数量
func (p *pool) WorkerCount() int32 {
return atomic.LoadInt32(&p.workerCount)
}
// work数量+1
func (p *pool) incWorkerCount() {
atomic.AddInt32(&p.workerCount, 1)
}
// work数量-1
func (p *pool) decWorkerCount() {
atomic.AddInt32(&p.workerCount, -1)
}
pool默认配置
// 默认的协程池实现
var defaultPool Pool
var poolMap sync.Map
func init() {
defaultPool = NewPool("gopool.DefaultPool", 10000, NewConfig())
}
func Go(f func()) {
CtxGo(context.Background(), f)
}
func CtxGo(ctx context.Context, f func()) {
defaultPool.CtxGo(ctx, f)
}
func SetCap(cap int32) {
defaultPool.SetCap(cap)
}
func SetPanicHandler(f func(context.Context, interface{})) {
defaultPool.SetPanicHandler(f)
}
func WorkerCount() int32 {
return defaultPool.WorkerCount()
}
func RegisterPool(p Pool) error {
_, loaded := poolMap.LoadOrStore(p.Name(), p)
if loaded {
return fmt.Errorf("name: %s already registered", p.Name())
}
return nil
}
func GetPool(name string) Pool {
p, ok := poolMap.Load(name)
if !ok {
return nil
}
return p.(Pool)
}
config
const (
defaultScalaThreshold = 1
)
type Config struct {
//最大协程数量
ScaleThreshold int32
}
// NewConfig 创建默认的配置
func NewConfig() *Config {
c := &Config{
ScaleThreshold: defaultScalaThreshold,
}
return c
}
代码已经上传github
文章来源于互联网:go思想下的池化并发技术-协程池实现

